Гибридный реконфигурируемый вычислитель.
С. С. Андреев, С. А. Дбар, А. О. Лацис, Е. А. Плоткина
- Инженерная методика адаптации приложения к гибридному кластеру с ускорителями на ПЛИС.
- Руководство программиста
- Руководство пользователя
- Сравнение технологий разработки схем вычислительного характера
Основные понятия.
Гибридный реконфигурируемый вычислитель – это универсальная ЭВМ, снабженная реконфигурируемым вычислительным модулем на базе ПЛИС. Вычислительная задача в целом решается на универсальной ЭВМ, некоторые вычислительно емкие фрагменты для ускорения счета реализуются в реконфигурируемом вычислительном модуле. Если объединить несколько гибридных реконфигурируемых вычислителей высокопроизводительной сетью, получится гибридно-параллельная реконфигурируемая вычислительная установка, или гибридный кластер с ускорителями на ПЛИС. Далее рассмотрим кратко устройство и функционирование отдельного гибридного реконфигурируемого вычислителя.
Для прикладного программиста использование реконфигурируемого модуля обычно выглядит, после выполнения необходимых подготовительных шагов, как обращение к функции (подпрограмме).
Универсальную ЭВМ в составе гибридного вычислителя будем далее для краткости называть процессором, а выполняющуюся на нем часть приложения – программой. Соответственно, реконфигурируемый вычислительный модуль будем называть сопроцессором, а описание реализуемой им вычислительной процедуры – схемой. Программа общается со схемой посредством набора функций доступа. Схема общается с программой через стандартный интерфейс схемы.
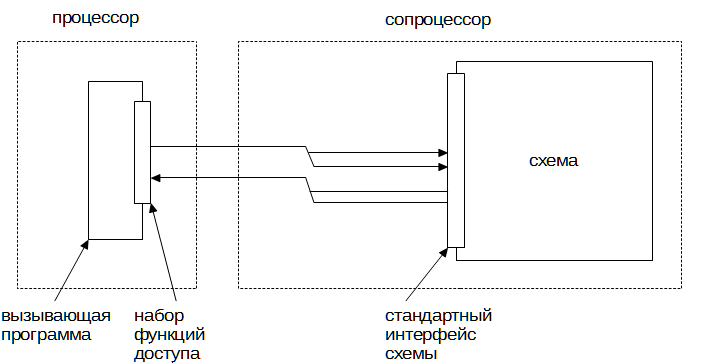
Рис. 1. Общая структура гибридного реконфигурируемого вычислителя.
Название "схема" здесь следует понимать буквально, в узко – "приборостроительном" смысле этого слова, что вполне отражает существо дела.
Как правило, вычислительное устройство (универсальный процессор, GPGPU, Xeon Phi) представляет собой электронную схему, внутреннее строение которой фиксировано раз и навсегда. В состав этой электронной схемы входит хотя бы одно устройство программного управления. Именно оно делает процессор универсальным: желая заставить его выполнять конкретный алгоритм, мы снабжаем его соответствующей программой. Реконфигурируемый вычислитель работает иначе. Он представляет собой своего рода "конструктор" - набор деталей, из которых можно построить любое цифровое электронное устройство - например, вычислительное устройство, способное выполнять одну, и только одну, необходимую нам, вычислительную процедуру. Будучи создано, ни в программном управлении, ни в программе такое устройство уже не нуждается. Реконфигурируемым вычислитель называется потому, что из входящего в его состав набора деталей можно строить произвольные цифровые электронные устройства неограниченное число раз. Именно это делает реконфигурируемый вычислитель универсальным: он может стать (в буквальном смысле слова, на аппаратном уровне) любым цифровым электронным устройством.
Чтобы реконфигурируемый вычислитель стал конкретным, реализующим определенную вычислительную процедуру, сопроцессором, необходимо разработать конкретную цифровую электронную схему (далее для краткости – просто схему), выполняющую требуемые вычисления. Разработка происходит путем написания текста, описывающего поведение требуемой схемы, на специальном языке, напоминающем язык программирования. Затем следует оттранслировать описание схемы в машинный формат (битовую последовательность), и загрузить битовую последовательность в вычислительный модуль. С этого момента реконфигурируемый вычислитель физически становится той схемой, описание которой в него загружено.
Может показаться, что различие между традиционным сопроцессором вроде GPGPU и реконфигурируемым вычислителем - мелкая, техническая деталь "внутренней кухни", не заслуживающая даже того краткого пояснения, которое было дано выше. В самом деле, в обоих случаях, для реализации конкретной вычислительной процедуры, необходимо описать ее на том или ином языке "программирования", и так ли важно для прикладного программиста, что именно происходит внутри компьютера в процессе трансляции и загрузки на выполнение этой "программы" или "схемы", как ее ни называй?
Формально это верно, по существу - нет. Использование реконфигурируемых вычислителей вместо давно и прекрасно себя зарекомендовавших процессоров с программным управлением может быть оправдано только заметным повышением быстродействия. Реконфигурируемость сама по себе не делает вычислитель быстрым - напротив, многократно его замедляет. Если, например, реализовать в реконфигурируемом вычислителе универсальный процессор (частный случай цифровой электронной схемы), и заставить этот процессор выполнять программу, описывающую необходимый нам алгоритм, мы не только не ускоримся, но многократно замедлимся (процессор получится плохой, гораздо худший, чем делают на заводе). Это замедление можно и нужно наверстать и многократно перекрыть, если правильно использовать потенциал специализации, "заточить" создаваемую схему под конкретную вычислительную процедуру, избавив ее от характерных для универсального процессора "узких мест". Но для этого нужны специальные языки (или хотя бы - специальные приемы) "программирования", адекватные целевому железу. Прикладной программист не сможет их ни понять, ни грамотно использовать, если не будет осознавать в общих чертах, с какой аппаратурой имеет дело - подобно тому, как невозможно осмысленно использовать ни MPI, ни языки вроде HPF или DVM, если не понимать разницы между однопроцессорным и многопроцессорным компьютером. Понимание коренного отличия реконфигурации от программирования, таким образом, необходимо хотя бы потому, что некоторые языки описания схем явно оперируют понятиями построения схемы, а не программирования процессора.
Перечислим основные документы, с которыми необходимо ознакомиться для прикладного программирования гибридного реконфигурируемого вычислителя, и дадим их краткую аннотацию. При этом нам придется ввести и пояснить еще несколько основополагающих понятий и терминов.
Если схема (файл с исходным текстом на соответствующем языке) изготовлена, ее надо уметь оттранслировать в битовую последовательность и загрузить в реконфигурируемый модуль - "прожечь". Это делается определенными командами, которые, вместе со всеми необходимыми опциями, описаны в Руководстве пользователя.
Прежде, чем приступать к проектированию и описанию схемы, необходимо проанализировать программный код приложения, и выделить в нем ту часть, которая больше всего выиграет от схемной реализации. Для начала важно понимать критерии такого выделения. Далее, весьма вероятно, что в имеющемся исходном тексте приложения такую часть выделить не удастся, но зато станет ясно, как именно следует переписать программный код, чтобы это удалось. Процесс поэтапной адаптации программного кода приложения к работе на гибридном реконфигурируемом кластере описан на конкретном примере в Инженерной методике адаптации приложения к гибридному кластеру с ускорителями на ПЛИС. Сразу отметим, что именно этот этап работы по переносу приложения на гибридный кластер является ключевым во всех отношениях, пренебрегать им ни в коем случае не следует. Тем более, что, как явствует из упомянутого документа, практически вся работа по адаптации приложения выполняется вполне традиционными программистскими средствами - нетрадиционна только цель этой адаптации. Очень важно понимать, что без глубокой реорганизации программной части приложения, схемная реализация какого-либо фрагмента этого приложения часто оказывается бессмысленной, не ускоряет, а замедляет работу приложения в целом.
Завершающей частью адаптации приложения является разработка и реализация схемы, то есть написание и отладка ее исходного текста. Технически это если и не самая трудная, то наверняка самая непривычная часть работы. Основным текстом, с которого рекомендуется начинать освоения технологии проектирования схем, является Руководство программиста на языке Автокод. Схему можно написать и более традиционными средствами - например, на языке C++, расширенном специальными директивами, но мы настоятельно рекомендуем тем, кто действительно хочет освоить ускорители на ПЛИС, начать с названного Руководства. Тому есть две причины.
Во-первых, неотъемлемой частью любой схемы является ее интерфейсная часть, "механика" взаимодействия схемы и программы. Для описания этой "механики" в деталях мы выбрали Руководство по Автокоду, поскольку в этом языке, в отличие от аннотированного C++, описываемые схемные понятия присутствуют в явном виде.
Во-вторых, есть еще одна очень важная причина для ознакомления с Автокодом Stream, даже если Вы не планируете в ближайшем будущем его использовать. Причина эта столь же традиционно упоминается во всех описаниях систем частичной автоматизации параллельного программирования, сколь традиционно (и совершенно зря) игнорируется читателями этих описаний. Язык С++, как и любой алгоритмический язык, разработанный для программирования процессоров, вообще-то довольно плохо подходит для описания эффективно работающих схем: в нем просто не хватает необходимых для этого понятий. Хотим мы это признавать или нет, в алгоритмическом языке слишком много от процессора. Полученная трансляцией с алгоритмического языка схема имеет очень большие шансы воспроизвести в своей работе все присущие процессору узкие места, а возможности оптимизации под конкретную вычислительную процедуру, напротив, не использовать в должной мере. Такая схема работает в разы, а то и в десятки раз, медленнее, чем могла бы, будь она спроектирована более явным образом. Для исправления этого недостатка транслятора из C++ в схему, текст на C++ аннотируется специальными директивами (прагмами), которые призваны помочь транслятору все-таки построить схему приемлемого качества. Подходящие прагмы практически невозможно "подобрать методом тыка", как мы часто делаем при выборе подходящих опций компиляции, чтобы получить более быструю программу для обычного процессора. Но для того, чтобы использовать аппарат прагм осознанно, необходимо понимать, хотя бы в самых общих чертах, чего хотеть от транслятора, какая схема в идеале должна получиться. А для этого, в свою очередь, необходимо представлять, что такое вообще эффективно работающая схема "на самом деле". Именно это представление и призвано дать читателю Руководство программиста на языке Автокод. В отличие от C++, этот язык как раз содержит в явном виде именно схемотехнические понятия, и в каком-то смысле даже придуман для их иллюстрации в наиболее "концентрированном" виде. Здесь просматривается явная аналогия с системами частичной автоматизации традиционного параллельного программирования, такими, как HPF и/или DVM. Хорошо известно, что наибольшего успеха в использовании этих систем достигают те прикладные программисты, которые в общих чертах знакомы с MPI, и, благодаря этому, понимают, какая примерно параллельная программа получится "на самом деле", если написать ту или иную прагму.
Использование прагм, конечно, позволяет значительно улучшить качество схемы, по сравнению с "голым" текстом на C++, но очень и очень многих проблем не решает все равно. Продвинутым программистам может быть интересно сравнение двух технологий разработки схем, а также приемы их комбинирования в одной схеме. Об этом рассказывается на конкретных примерах в документе Сравнение технологий разработки схем вычислительного характера.
Завершающая часть настоящего документа посвящена обзору технологии компиляции исходного текста схемы в битовую последовательность. Эта информация в равной степени полезна как читателю Руководства пользователя, так и читателю Руководства программиста.
Как мы уже знаем, исходно схема записывается на одном из двух прикладных языков схемотехнического проектирования - на Автокоде или на аннотированном C++. Трансляция каждого из этих языков происходит в два этапа.
На первом этапе текст на прикладном языке схемотехнического проектирования транслируется в текст на базовом языке схемотехнического проектирования - VHDL. Этот язык, в принципе, предназначен для записи и восприятия схем человеком, но, по ряду причин, довольно тяжел в изучении, и неудобен для непосредственного проектирования схем вычислительного характера, особенно для пректировщиков, не имеющих специальной радиоэлектронной подготовки. Непосредственно на VHDL обычно пишут профессиональные схемотехники. Тексты на VHDL, полученные в результате трансляции текстов на Автокоде, и особенно - на аннотированном C++, плохо читаются, поскольку вообще не предназначены для восприятия человеком, но формально являются все еще текстами. Время, занимаемое этим этапом трансляции - от нескольких секунд (для Автокода) до нескольких минут (для аннотированного C++). За счет своеобразной модели программирования, во многом не похожей на традиционную алгоритмическую модель, VHDL позволяет строить очень эффективные схемы (необходимые для этого понятия в языке присутствуют). Автокод проще и выше уровнем, чем VHDL, но реализует похожую модель программирования, за счет чего позволяет строить такие же эффективные схемы, используя потенциал VHDL в полной мере. Аннотированный C++, вообще говоря, проигрывает в эффективности создаваемых схем.
Трансляция текста на VHDL в битовую последовательность выполняется сложным программным комплексом - схемотехнической САПР, и сама является многоэтапной. Вдаваться в подробности этого процесса мы здесь не будем.
Нам достаточно знать, что весь этот процесс можно условно назвать синтезом схемы, что синтез – процесс длительный (для сложных схем занимает много часов), а результатом синтеза является электрически корректная схема, строго соответствующая оттранслированному тексту, или сообщение, что построить по заданному описанию электрически корректную схему из имеющихся ресурсов невозможно.
Причина такой невозможности, обычно, одна из двух. Либо схема просто слишком велика, и заведомо не умещается в данной модели ПЛИС (в "конструкторе", каковым является ПЛИС, просто не хватает "деталей" для такой большой, сложной "модели", как наша схема), либо схема имеет настолько сложную структуру требуемых связей "деталей" между собой, что их не удается реализовать на практике в данной модели ПЛИС. В последнем случае говорят о неудаче при трассировке схемы. Распространенным частным случаем неудачи при трассировке является наличие временнЫх ошибок. В этом случае трассировка схемы удается частично: требуемую структуру связей построить удается, но некоторые связи оказываются слишком длинными, чтобы устойчиво срабатывать на заданной для схемы рабочей частоте (а изменить эту частоту задним числом невозможно). В зависимости от конкретного распределения временных ошибок по цепям, такая схема может даже производить впечатление работающей, особенно на простых тестах, но действительно надежной, электрически корректной реализацией исходного текста ее считать нельзя. Конкретный вид диагностики об успехе или неудаче при синтезе схемы описывается в Руководстве пользователя.