Гибридный реконфигурируемый вычислитель. Руководствo программиста.
Структура Руководства программиста.
Часть 1. Примеры разработки схем на Автокоде HDL.
Пример №1 - сложение двух целых чисел.
Пример №2 - суммирование массива целых чисел.
Пример №3 - вычисление определенного интеграла с фиксированной точкой.
Пример №4 - поэлементное вычисление двух массивов целых чисел.
Примеры №№ 5, 6 - поэлементное вычисление массива вещественных чисел.
Пример №7 - вычисление определенного интеграла с плавающей точкой.
Многие читатели начинают знакомство с новой для них технологией программирования с «диагонального» знакомства с описанием, обращая основное внимание на примеры, чтобы «без лишней философии» понять, какого рода программы им придется писать, насколько высок уровень языка. Для такого первоначального знакомства с языком путем грубой визуальной оценки примеров настоящий документ совсем не годится. В этом качестве лучше использовать Часть 3 настоящего Руководства. Описываемые здесь примеры написаны на языке Автокод HDL, который представляет собой низкоуровневый слой языка Автокод. К реально используемым возможностям языка материал Части 1 относится примерно так же, как язык C к реализации C++ с богатой библиотекой готовых классов и шаблонов. К сожалению, мы не знаем пока способа объяснить реально используемые, высокоуровневые конструкции языка, не опираясь на общие понятия «уровня ассемблера». В то же время, для определения и пояснения общих понятий «уровня ассемблера» приходится приводить тривиальные примеры, совсем не похожие на реальные программы на высокоуровневом языке.
Таким образом, цель приводимых в Части 1 примеров состоит не в том, чтобы показать, как на самом деле выглядят составляемые пользователем схемы, а только в том, чтобы ввести базовые понятия, используемые в дальнейшем изложении. Базовые понятия - штука, плохо приспособленная для «диагонального» ознакомления. Тем не менее, если Вам вдруг требуется «наскоро» ознакомиться именно с базовыми понятиями, то «диагональный» просмотр настоящего документа - это то, что Вам нужно. Хотя, конечно, мы старались писать этот текст в расчете на кропотливое, вдумчивое освоение, с проникновением в детали. Впоследствии многие детали можно будет забыть, подобно тому, как опытный программист, освоив С или Фортран, забывает изучавшийся на первом курсе язык ассемблера, но сохраняет в своей памяти общие понятия фоннеймановской архитектуры компьютера, не зная которых, осилить тот же Фортран бывает нелегко.
Далее в тексте приводится несколько примеров схем. Текст схемы, как правило, разбит на части пояснениями, иногда довольно обширными. Чтобы упростить ориентацию читателя в тексте, начало и конец текста каждой схемы отмечены специальными фразами, набранными жирным курсивом:
Начало схемы примера Х:……Конец схемы примера Х.
Примеры занумерованы подряд от 1.
Первая схема на Автокоде (пример №1).
В качестве тривиального примера разработаем схему, вычисляющую сумму двух целых чисел. С практической точки зрения разработка такой схемы бессмысленна, но она позволит нам прояснить довольно много базовых понятий, в первую очередь - способ взаимодействия процессора с сопроцессором, и запись такого взаимодействия как со стороны программы, так и со стороны схемы.
С точки зрения программы, выполняющейся на универсальном процессоре, сопроцессор выглядит как набор регистров и областей памяти. Регистры соответствуют одиночным параметрам, значениями которых обмениваются программа и схема, области памяти - параметрам-массивам. В выбранном на сегодня конкретном варианте системы связи программы с сопроцессором регистров два, область памяти - одна. Ширина регистра равна ширине слова памяти, и может равняться 32, 64 или 128 битам, по выбору пользователя, размер области памяти - 4 мегабайта минус 64 байта.
Выбранную пользователем ширину регистра и слова памяти будем далее для краткости называть «платформенным размером» слова, имея в виду, что разработка схемы может вестись для 32-, 64- или 128-разрядной платформы. Целочисленный тип данных платформенного размера объявлен в стандартном заголовочном файле (см. ниже) как WORD. В случае 32-разрядной платформы WORD - это int, в случае 64-разрядной - long, в случае 128-разрядной - структура из двух полей, lowpart и highpart, оба поля - типа long. Здесь и далее предполагается, что используется 64-разрядный процессор и соответствующий компилятор языка С.
Для общения программы с сопроцессором используются стандартные функции, позволяющие копировать данные в обоих направлениях между данными программы, с одной стороны, и регистрами и/или областями памяти сопроцессора, с другой. Передача данных происходит всегда по инициативе программы. Используемые далее в примерах функции имеют вид:
void to_register(int nreg, WORD val)- записать значение val в регистр сопроцессора номер nreg,
void from_register( int nreg, WORD *val )- прочитать по адресу val значение из регистра сопроцессора номер nreg.
void to_coprocessor( int offs, void *arr, int leng )- записать массив arr длиной leng в область памяти сопроцессора, со смещением offs,
void from_coprocessor( int offs, void *arr, int leng )- прочитать данные из области памяти сопроцессора, со смещением offs, длиной leng, в массив arr.
В обоих случаях как длина массива, так и смещение в области памяти измеряются в словах платформенного размера.
Также имеется функция общей инициализации:
void init_coprocessor( int ns, int ne )- инициализировать систему коммуникаций данного процесса с сопроцессорами для сопроцессоров с номерами от ns до ne включительно. Сопроцессоры гибридного вычислительного узла занумерованы от 0 подряд. Поскольку хотя бы один сопроцессор в любой гибридной конфигурации присутствует по определению, мы во всех последующих примерах будем использовать заведомо правильную инициализацию в виде init_coprocessor(0, 0), что позволит управляющей программе использовать один из сопроцессоров (нулевой) гибридного вычислительного узла.
Как выглядит этот интерфейс на стороне сопроцессора, то есть из текста схемы на Автокоде?
Всякая схема на Автокоде начинается с заголовка, описывающего внешний интерфейс. Подобно тому, как любая программа на "C" начинается с
int main(int argc, char *argv[]) {
схема
на Автокоде имеет стандартный заголовок, вид и смысл которого
определяется соглашениями о внешнем интерфейсе. Заголовок для
32-разрядной платформы имеет вид:
program vector_proc_32 out 32 DO in 32 ADDR in 32 DI in 1 EN in 1 WE in 32 REG_IN_A in 32 REG_IN_B out 32 REG_OUT_A out 32 REG_OUT_B in 2 REG_WE_A in 2 REG_WE_B in 0 Clk in 0 Reset endprogram
Текст заголовка для 64- или 128-разрядной платформы можно получить заменой в приведенном заголовке всех вхождений текста «32» на «64» или «128», соответственно. Исключение - строка «in 32 ADDR». В ней для любой платформы сохраняется запись «32».
Каждая строка этого текста определяет именованный программный объект, похожий на формальный параметр процедуры в традиционных языках. Слово «in» означает, что параметр входной, «out» - что выходной. Параметры имеют имена и являются целочисленными. Число перед именем означает ширину значения в битах. Параметры Clk и Reset, ширина которых указана равной нулю, имеют специальный смысл. Их указание в заголовке обязательно, но в последующем тексте их упоминание может отсутствовать. Параметры DO, ADDR, DI, EN и WE связаны с реализацией видимой основному процессору области памяти, остальные - с регистрами A и B, соответственно. При этом регистру A на стороне процессора соответствует номер 6, регистру B - номер 7.
Рассмотрим, что происходит со значениями REG_IN_A, REG_WE_A и REG_OUT_A, когда программа на основном процессоре обращается к to_register(6, n) или from_register(6, &n).
В течение некоторого промежутка времени значение REG_WE_A, обычно равное 0, становится равным 1. В это же самое время REG_IN_A становится равным тому значению, которое программа на основном процессоре записала в регистр A. При попытке программы на основном процессоре прочитать регистр A она получит в ответ значение, ранее положенное схемой в REG_OUT_A. Регистр B работает точно так же.
Отложив совсем не надолго прояснение совершенно естественного вопроса о том, что такое «некоторый промежуток времени», напишем «наивную» (и, тем не менее, правильную) версию схемы на Автокоде, которая складывает значения, записанные в A и B, выдавая результат через A.
Начало схемы примера 1:program vector_proc_32
out 32 DO
in 32 ADDR
in 32 DI
in 1 EN
in 1 WE
in 32 REG_IN_A
in 32 REG_IN_B
out 32 REG_OUT_A
out 32 REG_OUT_B
in 2 REG_WE_A
in 2 REG_WE_B
in 0 Clk
in 0 Reset
endprogram
declare
reg 32 a
reg 32 b
reg 32 sum
enddeclare
REG_OUT_A = sum
Background:
{
[
a = 0
b = 0
sum = 0
]
if ( REG_WE_A == 1 )
a = REG_IN_A
endif
if ( REG_WE_B == 1 )
b = REG_IN_B
endif
sum = a + b
}
Конец схемы примера 1.
Управляющая программа для этой схемы могла бы выглядеть так:
#include <stdio.h>
#include <avtokod/comm.h>
int main( void )
{
WORD result;
init_coprocessor(0, 0);
from_register( 6, &result );
printf( "result: %d\n", result );
to_register(6, 2 );
to_register( 7, 3 );
from_register( 6, &result );
printf( "result: %d\n", result );
to_register( 7, 5 );
from_register( 6, &result );
printf( "result: %d\n", result );
return 0;
}
Пусть текст программы этого примера находится в файле primer_1.c, а текст схемы - в файле primer_1.avt. Тогда для запуска гибридного приложения необходимо выполнить следующее:
- Трансляция программы:
fpga_compile_32 -o primer_1 primer_1.c
Результат трансляции программы: исполняемый файл primer_1 - Трансляция схемы:
mpirun -np 1 -maxtime 200 `which avts` -vivado primer_1.avt
Результат трансляции схемы: битовая последовательность download.bit - Запуск программы с предварительным прожигом ускорителя битовой последовательностью:
mpirun -np 1 -maxtime 10 -resource fpga=k7 primer_1
Результат работы этой программы выглядит так:
result: 0 result: 5 result: 7
В первой строке выдачи мы не послали в сопроцессор никаких значений слагаемых, а сразу спросили результат. В ответ мы получили 0 - некоторое начальное значение по умолчанию. Во второй строке выдачи мы предварительно послали в первое слагаемое значение 2, во второе - значение 3, и получили сумму этих значений. В третьей строке мы изменили значение второго слагаемого с 3-х на 5, и снова получили сумму.
Теперь посмотрим, как при этом работала схема сопроцессора.
Как мы уже говорили, текст от «program» до «endprogram» представляет собой стандартный заголовок, вид которого характеризует не столько сам язык, сколько выбранный в конкретной операционной среде способ связи с внешним миром.
Далее, от «declare» до «enddeclare» идут объявления переменных. Простейшим видом переменной в Автокоде является скалярный регистр (reg). Он представляет собой именованное целочисленное значение указанной ширины в битах (32). Объявлены три регистра - a, b и sum. Первые два будут использоваться для хранения текущих значений слагаемых, третий - для хранения суммы. В данном случае ширина всех трех регистров одинакова и совпадает с платформенным размером слова, но это не обязано всегда быть так.
Далее следует раздел комбинационной логики, состоящий в этой схеме из единственной строки: REG_OUT_A = sum
По форме эта запись похожа на присваивание. По существу записи в этом разделе следует рассматривать, скорее, как алгебраические равенства. Смысл приведенной выше строки читается так: «Сделать значение выходного параметра REG_OUT_A тождественно равным (всегда) значению существующего внутри схемы регистра sum». Другими словами: «Жестко соединить выход sum со входом REG_OUT_A». Или даже еще проще: «Назвать выход sum синонимом - REG_OUT_A».
Комбинационные присваивания задают, таким образом, не действия, как операторы программы, а структуру схемы, и соответствуют, в конечном итоге, просто «припаиванию» выходов одних блоков схемы ко входам других. Уместна также алгебраическая аналогия. В алгебре запись: y = sin(x) означает, что для всех значений x, символ y есть результат применения к x функции «синус». Это отличается от смысла той же записи в программе на Фортране или С, предписывающей однократно выполнить вычисление синуса, и затем положить результат в переменную y. Как мы увидим далее, в Автокоде применяются оба вида присваиваний: и «алгебраические», и «алгоритмические». «Алгебраические» присваивания записываются в разделе комбинационной логики, «алгоритмические» - в других разделах схемы.
Текст в фигурных скобках, следующий сразу за заголовком «Background:», является разделом действий на каждом такте, в котором объединены две сущности раздела: секция начального сброса и, собственно, действия на каждом такте. Замечание: «Background» - не произвольный идентификатор, а ключевое слово языка.
Текст в квадратных скобках - это секция начального сброса (инициализации) схемы. В этой секции описываются действия (в привычном, алгоритмическом смысле слова), выполняемые схемой ровно один раз - при ее начальном пуске, то есть сразу после прожига ускорителя битовой последовательностью. Ни у программы, ни у самой схемы нет возможности «вернуться» в этот раздел. Все указанные в этом разделе действия выполняются схемой одновременно и независимо, порядок написания операторов присваивания в пределах секции не имеет значения. Условные операторы в этом разделе не допускаются.
Наконец, в фигурных скобках, следующих за заголовком «Background:», но вне квадратных скобок, идет текст действий, выполняемых схемой на каждом такте, или фоновых действий. В этом разделе описываются действия в алгоритмическом смысле этого слова, причем выполняемые схемой одновременно и независимо. В какой же именно момент (или моменты) времени выполняются эти действия?
Как только завершается процедура начального сброса и, соответственно, оказываются выполненными все действия одноименной секции, в схеме начинает течь глобальное дискретное время, состоящее из следующих друг за другом отдельных моментов, или тактов. На каждом таком такте выполняются все действия, записанные в данном разделе схемы.
Важно понимать, что действия каждого такта выполняются одновременно, причем в дискретном (а не в непрерывном, как в программе на С или Фортране) времени. При этом проверки, предусмотренные условными операторами, времени не занимают: выполнение условного оператора любой сложности укладывается в тот же такт, на котором будет выполнена выбранная по результатам проверки ветвь условного оператора. Напротив, присваивания занимают время, равное ровно одному такту, то есть результат присваивания становится «виден» на следующем после присваивания такте. В частности, из этого следует, что выполняемое на каждом такте суммирование a и b относится к «вчерашним», поступившим из программы на прошлом такте, значениям. Поскольку выполнение аппаратурой сопряжения процессора с сопроцессором функций to_register() и from_register() занимает заведомо больше одного такта, написанная таким образом схема является правильной.
Тем самым, данная часть раздела схемы есть просто тело бесконечного цикла.
У читателя - программиста в этом месте должен возникнуть совершенно закономерный вопрос: предусмотрена ли в Автокоде возможность записи привычных в традиционном программировании последовательных действий, выполняемых в том порядке, в котором они записаны, пусть и с поправкой на дискретность времени? Да, конечно, в реальных схемах такие действия записываются в завершающем разделе схемы - в разделе последовательных действий. Однако, в тривиальной схеме, рассмотренной только что, действий для этого раздела просто не нашлось, в силу ее (схемы) простоты.
Вторая схема: суммирование массива (пример №2).
Следующая схема, которую нам предстоит рассмотреть, гораздо сложнее предыдущей. Она также является бессмысленной с точки зрения практического использования, но позволяет проиллюстрировать большинство принципиальных возможностей Автокода, оставшихся «за кадром» при рассмотрении предыдущей, тривиальной, схемы.
Требуется разработать схему, выполняющую суммирование массива целых чисел указанной длины. Массив передается из программы в схему через область памяти, длина - через регистр A. Значение возвращается через регистр B.
Управляющая программа для этой схемы имеет вид:
#include <stdio.h>
#include <avtokod/comm.h>
#define L 128
int main( void )
{
int i;
WORD result;
static WORD array[L];
init_coprocessor( 0, 0 );
for ( i = 0; i < L; i++ ) array[i] = i;
to_coprocessor( 0, array, L );
to_register( 6, L );
done:
from_register( 6, &result );
if ( !result ) goto done;
from_register(7, &result );
printf( "result: %d\n", result );
return 0;
}
Пусть текст программы этого примера находится в файле primer_2.c, а текст схемы - в файле primer_2.avt. Тогда для запуска гибридного приложения необходимо выполнить следующее:
fpga_compile_32 -o primer_2 primer_2.c
mpirun -np 1 -maxtime 200 `which avts` -vivado primer_2.avt
mpirun -np 1 -maxtime 10 -resource fpga=k7 primer_2
Результат работы этой программы выглядит так:
result: 8128
Первое отличие этой схемы от предыдущей очевидно уже по тексту управляющей программы. В предыдущей схеме (и ее управляющей программе) мы сознательно не рассматривали проблему синхронизации программы и схемы на уровне действий программы. Времена срабатывания to_register() и from_register() настолько очевидно превосходят время выполнения сложения двух чисел, что специальной синхронизации от программы не требовалось, а схема могла позволить себе «на всякий случай» выполнять сложение текущих значений слагаемых на каждом такте. Довольно очевидно, что даже очень простые схемы, имеющие хоть какое-то отношение к решению реальных задач, так устроены быть не могут.
В теперешнем случае все обстоит иначе. Суммирование массива занимает, вообще говоря, длительное время, и схеме требуется получить от программы приказ начать работу: суммировать впрок, когда программа еще не записала данные в область памяти, довольно бессмысленно. В свою очередь, схема должна передать программе информацию о том, что работа окончена.
Из текста управляющей программы очевидно, как устроена эта синхронизация.
Сигналом начать работу для схемы служит факт записи программой значения в регистр A, в то время как само записанное значение рассматривается как длина массива, который надо просуммировать. Сигнал схемы о том, что работа окончена, передается через регистр A при его чтении программой. При инициализации схемы читаемое из этого регистра программой значение обнуляется, по окончании работы в него кладется единица. Результат суммирования к этому моменту уже доступен программе для чтения через регистр B.
Схема, выполняющая суммирование массива, в части рассмотренных нами на предыдущем примере разделов, выглядит так:
Начало схемы примера 2:program vector_proc_32
out 32 DO
in 32 ADDR
in 32 DI
in 1 EN
in 1 WE
in 32 REG_IN_A
in 32 REG_IN_B
out 32 REG_OUT_A
out 32 REG_OUT_B
in 2 REG_WE_A
in 2 REG_WE_B
in 0 Clk
in 0 Reset
endprogram
declare
reg 32 L
reg 32 sum
reg 32 ready
ram 32 array(ramb, 1, 16384)
enddeclare
REG_OUT_A = ready
REG_OUT_B = sum
array.dina[0] = DI
array.addra[0] = ADDR(23:0)
array.wea[0] = WE
DO = array.douta[0]
Background:
{
[
ready = 1
sum = 0
array.web[0] = 0
]
}
Прежде, чем дописывать схему до конца, разберем то новое, что принципиально отличает уже написанную часть схемы от схемы из предыдущего примера.
В первую очередь, конечно, бросается в глаза то, что раздел действий на каждом такте пуст. В этом нет ничего удивительного - тактируемые действия мы потом запишем в разделе последовательных действий, поскольку в дисциплину «делай на каждом такте одно и то же» они укладываются плохо. Сейчас же сосредоточимся на том новом, что появилось в разделах объявления переменных и комбинационной логики.
В разделе объявления переменных появился новый схемный объект, специфицируемый ключевым словом «ram». Это - массив векторной памяти, то есть объект, по смыслу похожий на массив традиционных языков программирования. Массив векторной памяти состоит из слов заданной при его объявлении разрядности (в данном случае - 32 бита), в количестве 16384 штук. Массив разбит на слои, или блоки, равного размера, причем каждый блок - это одномерный массив слов. В данном случае массив векторной памяти состоит из единственного слоя (блока).
Формально массив векторной памяти можно рассматривать как двумерный: индекс по первому измерению выбирает номер слоя, индекс по второму измерению - номер слова в слое. Индекс по первому измерению (номер слоя) обязан быть константой, значение которой известно во время компиляции, индекс по второму измерению (номер слова в слое) - может изменяться динамически, то есть быть регистром. Фактически такие массивы часто используются как массивы, хранящие векторы фиксированной длины (отсюда - название). Поскольку слои, на которые разбит массив, работают одновременно и независимо друг от друга, за одно обращение к массиву векторной памяти можно прочитать (или записать) вектор из такого количества слов, на сколько слоев разбит массив: каждое слово вектора будет читаться из (записываться в) отдельный слой. В последующих примерах мы увидим, как это делается.
Массив векторной памяти выглядит в схеме как набор регистров доступа к массиву, имена которых указываются вслед за именем массива, через точку, как поля структуры в традиционных языках программирования. Например, запись: array.douta[0] означает: «регистр выходных данных (dout) порта «a» нулевого слоя массива «array». Таким образом, каждый слой (блок) памяти имеет свой набор регистров доступа, значениями которых можно управлять независимо.
Смысл регистров доступа к блоку памяти следующий:
- регистр выходных данных доступен на чтение (может упоминаться в правой части оператора присваивания). Из этого регистра читается значение, лежащее по адресу, которому регистр адреса был равен на прошлом такте. Следовательно, чтобы получить значение из памяти, надо положить его адрес в регистр адреса, и на следующем после завершения присваивания адреса такте значение будет доступно в регистре выходных данных.
- регистр входных данных доступен на запись (может упоминаться в левой части оператора присваивания). Если значение требуется записать в некоторый адрес, его надо положить в регистр входных данных на том же такте, что и адрес - в регистр адреса. На этом же такте следует сделать равным единице регистр разрешения записи. На всех тактах, на которых запись не предусмотрена, регистр разрешения записи должен быть обнулен.
Таким образом, на каждом такте блок памяти:
- запоминает текущий адрес,
- если запись разрешена, выполняет запись регистра входных данных по этому адресу,
- в любом случае готовит к выдаче в регистре выходных данных на следующем такте хранимое по запомненному адресу значение.
Задаваемое при объявлении массива векторной памяти после слова «ram» число означает, как мы видели выше, разрядность хранящихся в массиве слов (и, тем самым, регистров входных и выходных данных). Разрядность адреса (регистра адреса) всегда равна 24-м. Далее в объявлении массива после его имени в круглых скобках указываются три параметра.
| Первый параметр: | тип массива, определяет конкретное число и названия портов. Каждый блок памяти имеет несколько независимых портов (блоков регистров доступа): как минимум, «a» и «b». На одном и том же такте с регистрами разных портов можно работать независимо: читать или писать по разным адресам. Непредсказуем лишь эффект одновременной записи в одну и ту же ячейку блока (запишется не одно из двух значений, а «мусор»). Выбор порта определяется последней буквой в названии регистра, назначение регистра - предыдущими буквами названия. Указанный при объявлении нашего массива тип «ramb» означает простую двухпортовую память: портов два, a и b, по каждому можно и читать, и писать. Другие типы массивов векторной памяти нам пока не понадобятся. |
| Второй параметр | означает число слоев, на которые разбит массив, называемое также его векторностью, или шириной. |
| Третий параметр | означает суммарный размер массива в словах (поделив ее на первую размерность, получим размер блока в словах). |
Как легко видеть, в комбинационной части схемы регистры доступа порта «a» блока «array[0]» соединены с одноименными интерфейсными регистрами диапазона памяти, доступного программе. Этого достаточно для того, чтобы обеспечить передачу массива из программы в схему. В самом деле, при выполнении обращения к функции to_coprocessor() аппаратура сопряжения процессора с сопроцессором выполняет передачу указанного программой массива согласно тем правилам, которые мы только что описали: перебирая значения адреса на интерфейсном регистре «ADDR», одновременно закладывает соответствующие значения элементов массива в регистр «DI», поддерживая равным единице регистр «WE». Чтение при выполнении «from_coprocessor()» происходит аналогично. Если, как в случае нашей первой схемы, использование интерфейсного диапазона памяти в схеме не предусмотрено, а программа все же выполнит, например, «to_coprocessor()», все ее усилия по передаче данных в схему пропадут напрасно: к регистрам, в которые программа трудолюбиво «вкачивает» содержимое массива, никакая реальная память в схеме не подключена. При выполнении программой «from_coprocessor()» в этом случае в программу будет прочитан «мусор». В данном же случае мы озаботились тем, чтобы за интерфейсным диапазоном стояла реальная память, и для этого подключили массив «array» к интерфейсным регистрам по порту «a». Для внутреннего доступа к этой памяти, схеме придется довольствоваться портом «b».
Выполнив все необходимые пояснения по использованию памяти, приступим к написанию оставшейся части схемы. Эта часть схемы будет представлена разделом последовательных действий, который в схеме из предыдущего примера отсутствовал. Работу раздела последовательных действий объяснить проще всего: изображаемая им часть схемы наиболее сильно напоминает запись программы на традиционном языке.
Сначала напишем цикл ожидания записи программой длины массива в интерфейсный регистр «A», означающий, что пора начинать работу, затем - цикл суммирования, после него - выдачу готовности через интерфейсный регистр «A» и возврат к первому циклу:
loop0:
{
if ( REG_WE_A == 1 )
L = REG_IN_A
array.addrb[0] = 0
ready = 0
sum = 0
else
next loop0
endif
}
{
array.addrb[0] = array.addrb[0] + 1
L--
}
loop1:
{
sum = sum + array.doutb[0]
array.addrb[0] = array.addrb[0] + 1
L--
if ( L != 0 )
next loop1
else
ready = 1
next loop0
endif
}
Конец схемы примера 2.
Операторы схемы, из которых состоит этот текст, имеют практически тот же смысл, что и операторы программы в традиционных языках программирования. Однако, несколько важных пояснений все же необходимо дать.
Как легко видеть, текст разбивается на группы операторов, заключенные в фигурные скобки (которые, кстати, обязательны в этом разделе схемы, даже если группа состоит из единственного оператора). Каждая такая группа представляет собой состояние схемы, то есть набор действий, выполняемых, одновременно и независимо, на одном такте. Результат присваивания при этом виден на следующем такте. Состояния выполняются, как операторы программы на традиционном языке, последовательно, в том порядке, в котором они записаны: следующий такт - следующее (по тексту) состояние. Оператор «next» - это оператор перехода, а упомянутые в нем идентификаторы - метки. Оператор этот намеренно назван словом, отличным от «goto», чтобы подчеркнуть, что это - не совсем «классический» оператор перехода. Переход, как и присваивание, отложен на такт. Все составляющие состояние операторы выполняются, с учетом условных проверок, и только после этого работает (или не работает) переход на указанное состояние. Ни «выйти по переходу» из состояния, не выполнив его до конца, ни перейти «внутрь какого-либо состояния» при помощи «next» невозможно, поскольку, как уже отмечалось выше, все операторы состояния выполняются одновременно и независимо. По этой же причине не важно, в каком порядке записаны операторы (в том числе «next») внутри фигурных скобок.
Рассмотрев второй пример схемы на Автокоде, мы можем теперь сформулировать ряд важнейших аспектов программистской модели этого языка в общем виде.
- В отличие от программ на традиционных языках, схема на Автокоде существенным образом двумерна: помимо последовательности действий, записываемой в разделах начального сброса, действий на каждом такте и последовательных действий (временное измерение), в схеме присутствует описание структуры (пространственное измерение), представленное разделом комбинационной логики. Пока мы использовали комбинационную логику только для организации связи схемы с внешним миром, но в более сложных, реальных схемах комбинационная логика широко используется также для построения внутренней структуры схемы.
- В отличие от программ на традиционных языках, время в схеме на Автокоде дискретно. Действия, выполняемые на любом данном такте, выполняются одновременно и независимо. При этом условные проверки любой степени сложности времени не занимают, а присваивания и переходы занимают ровно один такт, или, что то же самое, отложены на такт.
- В
отношении присваиваний регистрам значений действует правило
единственности источника значения. Оно состоит в том, что
каждому регистру можно присвоить значение либо только в разделе
комбинационной логики, причем только один раз, либо не более одного
раза на каждом такте. Например, если регистр используется в левой
части безусловного оператора присваивания в разделе действий на
каждом такте, то в разделе последовательных действий ему уже ничего
присваивать нельзя. Менее очевидный пример: если в программах на С мы
часто пишем что-то вроде:
a = b; if( n ) a = c;то в схеме на Автокоде следует писать:{ if ( n != 0 ) a = c else a = b endif }поскольку в одном состоянии (на одном такте) нельзя сначала присвоить регистру «a» одно, а затем - другое. Такт - это квант времени, не имеющий протяжения, т.е. никаких «сначала» и «потом» внутри такта нет. - Автокод является языком спецификации схемы с точностью до такта (cycle-accurate language). Это означает, что программист контролирует скорость работы схемы с абсолютной точностью, подобно тому, как программист на языке ассемблера с абсолютной точностью контролирует двоичный образ разрабатываемой им программы, хотя и не выписывает вручную составляющую эту программу биты. Отсюда - название языка: когда-то давно языки, называемые сегодня языками ассемблера, в русскоязычной терминологии назывались «автокодами один в один».
Более сложная схема: вычисление определенного интеграла методом трапеций с фиксированной точкой (пример №3).
Возвращаясь к рассмотренным примерам схем, мы вынуждены отметить, что они пока никак не демонстрируют даже потенциальных преимуществ именно схемной реализации вычислений. В самом деле, рабочие частоты ПЛИС на порядок ниже рабочих частот современных процессоров общего назначения. Для того, чтобы получить скоростной выигрыш, совершенно необходимо писать схемы, выполняющие за такт не одну, а несколько арифметических операций. Попробуем написать действительно эффективную схему вычисления определенного интеграла с фиксированной точкой методом трапеций. Если мы допустим, что интегрируемая функция задана таблично на равномерной сетке, а данные нормированы таким образом, что шаг равен 1, задача фактически сведется к предыдущей, с одним уточнением: суммируя массив, значения его первого и последнего элементов требуется поделить пополам. Кроме того, будем выполнять одновременно не одно, а восемь сложений. Для простоты потребуем также, чтобы размер сетки, на которой задана интегрируемая функция, делился на 8.
Очевидно, менять управляющую программу по сравнению с предыдущим примером нам не потребуется.
Пусть текст программы этого примера находится в файле primer_3.c, а текст схемы - в файле primer_3.avt. Тогда для запуска гибридного приложения необходимо выполнить следующее:
fpga_compile_32 -o primer_3 primer_3.c
mpirun -np 1 -maxtime 200 `which avts` -vivado primer_3.avt
mpirun -np 1 -maxtime 10 -resource fpga=k7 primer_3
Результат работы этой программы на этот раз выглядит так:
result: 8064
Приступим к написанию схемы. Как и в предыдущем примере, разобьем схему на две части, чтобы проще было давать пояснения.
Начало схемы примера 3:program vector_proc_32
out 32 DO
in 32 ADDR
in 32 DI
in 1 EN
in 1 WE
in 32 REG_IN_A
in 32 REG_IN_B
out 32 REG_OUT_A
out 32 REG_OUT_B
in 2 REG_WE_A
in 2 REG_WE_B
in 0 Clk
in 0 Reset
endprogram
declare
reg 32 L
reg 32 sum
reg 32 ready
ram 32 array(ramb, 8, 16384)
reg 3 old_addr_low
reg 32 partsum(8)
reg 32 dout_half(8)
enddeclare
REG_OUT_A = ready
REG_OUT_B = sum
do @1 = 0, 7
array.dina[@1] = DI
array.addra[@1](23:0) = ADDR(26:3)
array.wea[@1] = ( (@1 == ADDR(2:0)) && (WE == 1) ) ? 1 : 0
DO = ( @1 == old_addr_low ) ? array.douta[@1] : 'Z'
dout_half[@1](30:0) = array.doutb[@1](31:1)
dout_half[@1](31:31) = 0
enddo
Background:
{
[
ready = 1
sum = 0
partsum = 0
array.web = 0
L = 0
]
old_addr_low = ADDR(2:0)
}
Для того, чтобы обеспечить одновременное выполнение восьми операций сложения, нам потребуется массив из восьми (а не одного, как в предыдущем примере) блоков памяти. Написав: ram 32 array(ramb, 8, 16384), мы это учли. Как нам теперь подключить этот массив к интерфейсной области памяти? Нам ведь требуется, чтобы поступающие из программы значения раскладывались по блокам массива с периодом 8: нулевое слово массива - в нулевое слово нулевого блока, первое слово массива - в нулевое слово первого блока, второе слово массива - в нулевое слово второго блока, …, восьмое слово массива - в первое слово нулевого блока, и т. д.
Для решения этой проблемы мы написали в разделе комбинационной логики цикл «do» - все, что расположено от «do» до «enddo», включительно. Синтаксически запись довольно очевидна. Переменная цикла не была (и не должна быть) объявлена в разделе объявления переменных, поэтому имеет специальный вид «@1» (вместо единицы можно было использовать любую цифру больше 0). Сначала рассмотрим, как выполнено подключение массива векторной памяти на прием данных из программы. Поскольку восемь (число блоков в массиве) - степень двойки, мы может расщепить адрес слова в массиве, поступающий из программы, на два поля. Младшие три бита мы будем трактовать как номер блока в массиве (от 0 до 7), а старшие биты - как номер слова в блоке. В Автокоде диапазон битов в пределах регистра задается в круглых скобках через двоеточие, например: ADDR(23:3), ADDR(2:0).
Теперь мы можем подать поступающее из программы значение (DI) на входы данных всех блоков, старшую часть адреса (ADDR(23:3)) - на адресные входы всех блоков, а младшую часть адреса использовать для выборочной подачи разрешения записи на тот блок массива, номеру которого она равна. Формально анализируя текст тела цикла «do», легко убедиться, что именно это там и написано.
Может возникнуть вполне законный вопрос: где и в каком ритме выполняется этот цикл «do», сколько тактов занимает, и почему записан в комбинационном разделе схемы? Ответ прост. Данный цикл выполняется при трансляции схемы, и только. Он является не более чем сокращенной формой записи восьми отдельных комбинационных соотношений, каждое из которых имеет традиционный для комбинационного раздела «алгебраический» смысл (переменную цикла при этом следует трактовать как свободную переменную). Попросту говоря, это цикл не выполнения, а построения схемы, цикл в пространстве, а не во времени. В готовой схеме, во время ее работы, никакого цикла нет. Конечно, границы изменения переменной такого цикла должны быть константами, что в нашем случае имеет место.
Несколько сложнее обстоит дело с реализацией передачи данных через интерфейсную область памяти в обратную сторону, из схемы в программу. Хотя наше приложение такой передачи данных и не предусматривает (управляющая программа не содержит обращений к «from_coprocessor()»), все же реализуем в схеме необходимые подключения. Проблем здесь две.
Во-первых, данные из памяти, как мы знаем, считываются с задержкой на такт относительно записи адреса. Это значит, что нам потребуется не «сегодняшнее», а «вчерашнее» значение младшей части адреса, чтобы разобраться, так или иначе, с выбором блока.
Во-вторых, само разбирательство с выбором блока грозит непредвиденно усложниться. В самом деле, если в только что рассмотренном случае приема данных в схему мы развели поступающие данные из одного источника (DI) на восемь блоков, то сейчас нам потребуется решить обратную задачу: каким-то образом свести выходы с восьми блоков в один интерфейсный регистр DO.
Начнем с первой проблемы. Ее решение тривиально. Чтобы постоянно иметь в своем распоряжении «вчерашнее» значение младшей части адреса, объявим специальный регистр «old_addr_low», и будем присваивать ему младшую часть адреса на каждом такте. Поскольку присваивание, как мы знаем, выполняется с задержкой на такт, проблема решена. Расположено это присваивание, естественно, в разделе действий на каждом такте.
Решение второй проблемы записано в последней строке тела цикла, непосредственно перед «enddo»:
DO = ( @1 == old_addr_low ) ? array.douta[@1] : 'Z'
Как мы уже отмечали, эта запись в теле цикла эквивалентна следующим восьми операторам, записанным без использования цикла:
DO = ( 0 == old_addr_low ) ? array.douta[0] : 'Z' DO = ( 1 == old_addr_low ) ? array.douta[1] : 'Z' …… DO = ( 7 == old_addr_low ) ? array.douta[7] : 'Z'
«Расшифруем», например, первый из этих операторов. В нем записано: «Если значение регистра old_addr_low равно 0, то считать, что DO тождественно равно array.douta[0], иначе не считать значение DO определенным в данном операторе». Символ 'Z' специально предназначен для записи конструкций такого рода, которые в схемотехнике называют мультиплексорами. Использование мультиплексоров не противоречит правилу единственности источника значения, если области определения ветвей мультиплексора не пересекаются. В данном случае они точно не пересекаются: значение old_addr_low может быть равно в каждый момент времени лишь одному числу в диапазоне от 0 до 7. Использование некорректных (с пересекающимися областями определения ветвей) мультиплексоров ведет к построению транслятором, вообще говоря, электрически некорректных схем, эффект от работы которых подобен эффекту выхода за границы массива в программе на традиционном языке программирования.
Завершая анализ представленной выше части схемы, отметим еще два отличия от предыдущих примеров.
В разделе объявлений переменных появился векторный регистр partsum, состоящий из восьми скалярных регистров. Это одномерный массив, индексировать который можно только значением, известным во время трансляции схемы - например, константой или переменной цикла. Такими же векторными регистрами являются регистры доступа к массиву векторной памяти, например, array.web или array.addra.
Векторным регистрам можно присваивать скалярные константы. Это воспринимается как «пространственный» цикл присваивания константы каждому из элементов вектора. В разделе начального сброса, например, написано:
array.web = 0но можно было написать и:
do @1 = 0, 7
array.web[@1] = 0
enddo
Основная часть раздела последовательных действий нашей схемы является естественным обобщением схемы из предыдущего примера на векторный случай, с некоторым усложнением за счет того, что первый и последний элементы массива надо перед суммированием поделить пополам:
loop0:
{
if ( REG_WE_A == 1 )
L(28:0) = REG_IN_A(31:3)
array.addrb = 0
ready = 0
sum = 0
else
next loop0
endif
}
{
array.addrb = array.addrb + 1
L--
}
loop1:
{
do @1 = 0, 7
if ( ((@1 == 0) && (array.addrb[0] == 1)) || ((@1 == 7) && (L == 0)) )
partsum[@1] = partsum[@1] + dout_half[@1]
else
partsum[@1] = partsum[@1] + array.doutb[@1]
endif
enddo
array.addrb = array.addrb + 1
L--
if ( L != 0 )
next loop1
endif
}
Очевидно, что к этому моменту схема не дописана. В самом деле, мы вычислили в векторном регистре partsum восемь частичных сумм, которые для получения окончательного результата необходимо всего лишь сложить между собой. Рука сама тянется написать что-то вроде
do @1 = 0, 7
sum = sum + partsum[@1]
enddo
но
разум подсказывает, что так делать нельзя. Цикл «do»,
как мы знаем, пространственный, а не временной, и ничего, кроме
вопиющего нарушения правила единственности источника значения, из
приведенной только что записи не получится. Тогда, может быть,
следует написать:
sum = partsum[0] + partsum[1] + partsum[2] + ……
Такая запись формально правильна, но трансляция схемы с ней заведомо окончится ошибкой. Электронное устройство, складывающее сразу восемь чисел, очень сложное, и тактовая частота, на которой оно смогло бы работать, во много раз ниже, чем частота, на которой способно работать все написанное нами до сих пор. А ведь в схеме на Автокоде может быть всего одна частота. Обычно она подбирается такой, чтобы суммирование или вычитание двух целых чисел платформенного размера укладывалось в один такт с некоторым небольшим запасом. Поэтому записей сложных выражений в схеме следует избегать. Придется разбить суммирование частичных сумм на такты вручную:
{
do @1 = 0, 3
partsum[@1] = partsum[@1] + partsum[@1+4]
enddo
}
{
do @1 = 0, 1
partsum[@1] = partsum[@1] + partsum[@1+2]
enddo
}
{
sum = partsum[0] + partsum[1]
ready = 1
next loop0
}
Конец схемы примера 3.
Теперь схема написана окончательно.
Четвертая схема: вычисление двух массивов (пример №4).
Если в предыдущем примере были показаны ускорения вычислений на ПЛИС за счет векторизации (одновременное выполнение одинаковых вычислений, за счет увеличения длины вектора памяти), то в этом примере ускорения будем добиваться за счет одновременного выполнения различных вычислений. Заодно выясним, как принимать в схему и выдавать из нее несколько массивов.
Разработаем схему, выполняющую следующие вычисления:
arr_C = arr_A + arr_B
arr_D = arr_A * num
где arr_A
и arr_B
- два исходных массива целых чисел указанной длины L,
num - целое число,
arr_C
и arr_D
- массивы результатов вычислений.
Из программы в схему необходимо передать: через регистры - число num и длину массива L, через область памяти - массивы arr_A и arr_B; в программу из схемы принять массивы результатов arr_C и arr_D. В схеме для каждого массива выделяется свой ram - массив векторной памяти. Как схема "поймет", что поступающие данные надо записывать в ram arr_A, а не в arr_B, что выдавать результаты надо из ram'а arr_C, а не из arr_D? В этом случае придется адресовать не только данные внутри массивов, но и сами массивы. Для этого перед записью массива в схему или перед чтением массива из схемы придется передавать через регистр номер ("адрес") массива.
Дадим массивам следующие адреса:
0 - arr_A; 1 - arr_B; 2 - arr_C; 3 - arr_D.
Тогда управляющая программа для схемы будет иметь вид:
#include <stdio.h>
#include <avtokod/comm.h>
#define L 128
int main( void )
{
int i, num;
WORD result;
static WORD arr_A[L], arr_B[L], arr_C[L], arr_D[L];
init_coprocessor( 0, 0 );
num = 4;
for ( i = 0; i < L; i++ )
{
arr_A[i] = i;
arr_B[i] = i;
arr_C[i] = 0;
arr_D[i] = 0;
}
to_register_masked_int( 7, 0, num ); // передача в схему числа num
to_register_masked_int( 7, 1, 0 ); // передача в схему адреса ram arr_A = 0
to_coprocessor(0, arr_A, L ); // запись массива в ram arr_A
to_register_masked_int(7, 1, 1 ); // передача в схему адреса ram arr_B = 1
to_coprocessor(0, arr_B, L ); // запись массива в ram arr_B
to_register( 6, L );
done:
from_register(6, &result );
if ( !result ) goto done;
to_register_masked_int(7, 1, 2 ); // передача в схему адреса ram arr_C = 2
from_coprocessor(0, arr_C, L ); // чтение массива из ram arr_С
to_register_masked_int(7, 1, 3 ); // передача в схему адреса ram arr_D = 3
from_coprocessor(0, arr_D, L ); // чтение массива из ram arr_С
for ( i =0; i < L; i++ )
{
printf( "arr_C[%d] = %d; arr_D[%d] = %d;\n",
i, arr_C[i], i, arr_D[i] );
}
return 0;
}
В этой программе мы видим обращение к не встречавшейся нам ранее функции to_register_masked_int(). Это "экономный" вариант записи в значения в интерфейсный регистр. "Экономность" здесь двоякая. Во-первых, записывается не весь регистр, а только старшие 32 разряда (отсюда int в названии функции). Для 32-разрядной платформы весь интерфейсный регистр как раз и состоит из 32-х разрядов, так что регистр все равно передается целиком, но для 64- или 128-разрядной платформы, за счет передачи только 32 разрядов, а не всего регистра, действительно, возможна некоторая экономия времени синхронизации. Во-вторых, эта функция позволяет управлять тем, какой именно бит регистра признака записи (REG_WE_A, REG_WE_B) "загорается" на стороне схемы при поступлении значения из программы в соответствующий интерфейсный регистр. Во всех предыдущих примерах мы использовали для записи значений в интерфейсный регистр функцию "to_register()", а соответствующий регистр признака записи менял свое значение с нуля на единицу. Но ведь, согласно заголовку схемы, регистр признака записи содержит не один, а два разряда. Значит, при обращении в программе к to_register() "загорается" всегда нулевой, или младший, разряд. В действительности, программа может задать в явном виде номер разряда регистра признака записи, который будет "загораться" при поступлении значения из программы в схему, обратившись к функции to_register_masked() или to_register_masked_int(). Первый аргумент этих функций задает номер интерфейсного регистра, второй - номер разряда в нем, который при записи должен стать равным единице (нумерация разрядов - справа налево, от нуля), третий - записываемое значение. Возможность выбирать в программе номер разряда, сигнализирующего о записи значения в схему, позволяет дополнительно "подкрасить" это значение и, тем самым, уменьшить число требуемых записей управляющего плана.
Пусть текст программы этого примера находится в файле primer_4.c, а текст схемы - в файле primer_4.avt. Тогда для запуска гибридного приложения необходимо выполнить следующее:
fpga_compile_32 -o primer_4 primer_4.c
mpirun -np 1 -maxtime 200 `which avts` -vivado primer_4.avt
mpirun -np 1 -maxtime 10 -resource fpga=k7 primer_4
Результатом работы этой программы будет распечатка массивов arr_C и arr_D в виде:
arr_C[i] = i+i; arr_D[i] = i * 4;
Приступим к написанию схемы.
Начало схемы примера 4:program vector_proc_32
out 32 DO
in 32 ADDR
in 32 DI
in 1 EN
in 1 WE
in 32 REG_IN_A
in 32 REG_IN_B
out 32 REG_OUT_A
out 32 REG_OUT_B
in 2 REG_WE_A
in 2 REG_WE_B
in 0 Clk
in 0 Reset
endprogram
declare
ram 32 arr_A(ramb, 1,512)
ram 32 arr_B(ramb, 1,512)
ram 32 arr_C(ramb, 1,512)
ram 32 arr_D(ramb, 1,512)
reg 32 ready
reg 32 num
reg 24 L
reg 24 addr_read
reg 24 addr_write
reg 2 address_ram
enddeclare
{arr_A.dina, arr_B.dina} = DI
{arr_A.addra, arr_B.addra} = ADDR(23:0)
arr_A.wea = (address_ram == 0) ? WE : 0
arr_B.wea = (address_ram == 1) ? WE : 0
{arr_C.addrb, arr_D.addrb} = ADDR(23:0)
DO = (address_ram == 2) ? arr_C.doutb : arr_D.doutb
{arr_A.addrb, arr_B.addrb} = addr_read
{arr_C.addra, arr_D.addra} = addr_write
REG_OUT_A = ready
В разделе объявлений переменных объявлено 4 ram'а: arr_A, arr_B, arr_C и arr_D.
В arr_A и arr_B будут записываться массивы исходных данных из управляющей программы и читаться эти данные для вычислений, в arr_C и arr_D будут записываться результаты вычислений, и затем управляющая программа будет их читать. Для всех ram'ов порт 'a' будем использовать для записи, порт 'b' - для чтения.
В комбинационной части записаны связи между портами ram'ов и портами самой схемы. Как видно, входные данные DI и входной адрес ADDR соединены со входами порта 'a' ram'ов arr_A и arr_B безусловно. А вот сигнал записи WE на arr_A.wea поступит только при условии address_ram = 0, а на arr_B.wea - когда address_ram = 1. Для чтения массивов из схемы ситуация аналогичная: входной адрес ADDR на arr_C.addrb и arr_D.addrb подается безусловно, а на выходной порт DO подается arr_C.doutb, если address_ram = 2, иначе arr_D.doutb.
Поскольку читать исходные данные внутри схемы из arr_A и arr_B будем одновременно, то логично завести один счетчик адресов addr_read и комбинационно соединить его со входами arr_A.addrb и arr_B.addrb. Тогда любое изменение счетчика будет мгновенно передаваться на данные регистры. Счетчик адресов для записи результатов в arr_C и arr_D в этом примере выполняет ту же функцию, хотя в реальных задачах результаты вычислений практически всегда имеют разную задержку, поэтому приходится иметь счетчик адресов для записи у каждого ram'а свой.
Продолжение схемы примера 4:Background:
{
[ready = 1 ]
if(REG_WE_B == 1)
num=REG_IN_B
elsif(REG_WE_B == 2)
address_ram=REG_IN_B(1:0)
endif
if(arr_C.wea == 0)
addr_write = 0
else
addr_write++
endif
}
В разделе действий на каждом такте пишем:
- Инициализация переменных в секции начального сброса.
Здесь записан только один оператор: ready = 1 (схема свободна и готова к работе).
В предыдущем примере говорилось о том, что, при наличии в схеме блоков памяти ram, все не используемые регистры .wea и .web этих блоков должны быть обнулены. Это действительно очень важно, т.к. в противном случае при работе схемы будут возникать ошибки, которые крайне тяжело идентифицировать. С другой стороны, при использовании в схеме большого числа блоков памяти, очень легко забыть обнулить какой-нибудь из регистров разрешения записи по не используемому порту. Поэтому транслятор проверяет наличие присваиваний в регистры разрешения записи в память в комбинационной части и в секции начального сброса, и, если их не находит, то сам обнуляет соответствующие регистры разрешения по начальному сбросу.
- Прием в схеме аргумента num.
Он появится на REG_IN_B в момент REG_WE_B = 1 (это произойдет после вызова функции to_register_masked_int( 7, 0, num ));
- Прием в схеме аргумента address_ram.
Он будет появляться на REG_IN_B в момент REG_WE_B = 2 (это будет происходить после вызова функции to_register_masked_int( 7, 1, N ), где N - адрес ram'а);
- Формирование адресов на счетчике адресов записи addr_write.
Когда еще нечего записывать в память и arr_C.wea = 0 (присваивать значения arr_C.wea и arr_D.wea мы будем ниже, в разделе состояний), то соответственно значение addr_write тоже будет равным 0. Когда arr_C.wea станет равной 1, то первый результат запишется по адресу 0. Но, поскольку на этом такте мы увеличим addr_write на 1, то на следующем такте следующий результат запишется уже по адресу 1. Увеличение адресов будет продолжаться до тех пор, пока arr_C.wea снова не станет равным 0, и не сбросит в 0 addr_write.
loop0:
{
if(REG_WE_A == 1)
L = REG_IN_A(23:0)
addr_read = 0
ready = 0
else
next loop0
endif
}
{
addr_read++
}
loop1:
{
arr_C.dina = arr_A.doutb + arr_B.doutb
arr_D.dina = arr_A.doutb * num
arr_C.wea = 1
arr_D.wea = 1
if( addr_read < L )
addr_read++
next loop1
endif
}
{
arr_C.wea = 0
arr_D.wea = 0
ready = 1
next loop0
}
Конец схемы примера 4
Раздел последовательных действий состоит из в 4-х состояний.
Первое состояние (метка loop0) - это цикл ожидания последнего аргумента L (длина массива), сопровождать который будет признак записи REG_WE_A = 1. По этому сигналу сохраним в переменной L значение входного регистра REG_IN_A (т.к. этот параметр мы будем сравнивать со счетчиком адресов addr_read, то и разрядность регистра L необходимо задать такой же, как и addr_read, т.е. равной 24). Поскольку данный аргумент - последний, то можно считать это признаком начала работы. Поэтому здесь же сбросим в 0 сигнал готовности схемы и зададим начальный адрес считывания
addr_read = 0На следующем такте перейдем во 2-е состояние.
Второе состояние будет длиться 1 такт и состоять из одного оператора
addr_read++Затем, на следующем такте, схема перейдет в третье состояние. Зачем понадобилось делать 2-е состояние, с увеличением адреса на 1? Нам необходимо выполнять потоковые вычисления, это означает, что на каждом такте из памяти последовательно должны поступать числа, лежащие по адресам от 0 до L. Следовательно, на каждом такте должны меняться от 0 до L адреса памяти. Но адрес после присваивания появится на следующем такте, а число, лежащее в памяти по этому адресу, появится еще на такт позже. То есть числа на выходных регистрах памяти мы "увидим" через такт, а адреса чтения менять нужно каждый такт.
Третье состояние будет длиться L-1 такт. В этом состоянии мы записываем в arr_C.dina сумму arr_A.doutb и arr_B.doutb, в arr_D.dina произведение arr_A.doutb и num, а на arr_C.wea и arr_D.wea подаем 1. Фактически запись в память arr_C и arr_D начнется со следующего такта, т.к. результат присваиваний отложен на такт. Пока addr_read < L, будет увеличиваться счетчик адресов и формироваться возврат в 3-е состояние. Последний такт 3-го состояния будет в ситуации, когда addr_read станет равным L, if не выполнится, а на arr_C.dina и на arr_D.dina подадутся суммы последних элементов массивов arr_A и arr_B. Поскольку запись этих сумм произойдет только на следующем такте, то признаки записи в память снимать еще рано. Необходимо еще одно состояние.
Четвертое состояние будет длиться 1 такт. В нем фактически происходит последняя запись в память, поэтому именно на этом такте нужно закрыть запись, чтобы ничего лишнего в память на следующих тактах не записалось. В этом же такте ставим ready = 1 (признак окончания вычислений) и формируем переход в 1-е состояние, в котором схема будет находиться до следующего обращения управляющей программы.
Пятая схема: поэлементное вычисление массива вещественных чисел (примеры №№5 и 6).
К сожалению, современные ПЛИС не умеют, подобно универсальным процессорам, выполнять арифметические операции с плавающей точкой так же быстро, как с фиксированной (на самом деле, иногда умеют, но это очень затратно по ресурсам, и этой возможностью лучше не пользоваться). По этой причине соответствующие типы данных и операции над ними в Автокод не включены. При вычислениях с плавающей точкой значения хранятся в регистрах достаточной разрядности, а сами вычисления выполняются путем использования специальных библиотечных компонентов, вставляемых в схему. Слово «компонент» в данном случае - не эпитет, а термин. Структурно компонент имеет довольно много общего с функцией (подпрограммой) традиционных языков программирования, но, с учетом различий в моделях программирования, по смыслу сильно от нее отличается. Целей построения настоящего примера - две:
- освоить использование компонентов,
- научиться строить конвейерные схемы.
Компоненты для вычислений с плавающей точкой обычно бывают способны выдавать результат лишь через некоторое, заметно большее единицы, число тактов после подачи на них исходных данных. При этом, они способны принимать новые «комплекты» данных на каждом такте. В результате, при «прокачке» через компонент массива данных мы получаем на выходе поток результатов, задержанный, например, на 5 или 10 тактов относительно входного потока. Производительность схемы при этом практически не страдает: в среднем за длительное время ритм обработки не отличается от ритма обработки данных с фиксированной точкой, но, к сожалению, значительно усложняется строение схемы.
Работающие в таком режиме схемы называются конвейерными, и это - основной режим работы подавляющего большинства схем вычислительного характера. Для того, чтобы строить конвейерные схемы, приходится интенсивно использовать комбинационную логику и аппарат компонентов.
Подобно тому, как в традиционных языках программирования программу принято делить на транслируемые отдельно функции или подпрограммы, вызывающие друг друга, схема на Автокоде может состоять из нескольких компонентов - отдельных схем, по мере надобности вставляемых (встраиваемых) друг в друга. Опять же в полной аналогии с традиционными языками программирования, любая схема на Автокоде является компонентом, вставляемым в некоторую стандартную среду исполнения. Так, каждая из рассмотренных нами выше схем в действительности представляет собой компонент, хотя мы до поры до времени ничего об этом не говорили. Еще одно сходство с аппаратом подпрограмм и функций традиционных языков состоит в том, что предусмотрен унифицированный способ связи между компонентами, в чем-то похожий на аппарат передачи параметров в традиционных языках. Как и в случае традиционных языков, наличие такого унифицированного способа связи позволяет использовать компоненты, разработанные в других технологиях программирования (например, написанные на других языках), в том числе - библиотечные.
На этом сходство с функциями и подпрограммами традиционных языков заканчивается, начинаются различия.
Прежде чем строить содержательный пример, проиллюстрируем понятие компонента в совсем тривиальном случае. Перепишем нашу самую первую схему, складывающую два числа, заменив встроенную в Автокод операцию сложения двух целых чисел компонентом «сумматор с фиксированной точкой».
Начало схемы примера 5:program vector_proc_32
out 32 DO
in 32 ADDR
in 32 DI
in 1 EN
in 1 WE
in 32 REG_IN_A
in 32 REG_IN_B
out 32 REG_OUT_A
out 32 REG_OUT_B
in 2 REG_WE_A
in 2 REG_WE_B
in 0 Clk
in 0 Reset
endprogram
declare
reg 32 a
reg 32 b
reg 32 sum
component summator5
enddeclare
REG_OUT_A = sum
insert summator5
.add1( a )
.add2( b )
.result( sum )
.Clk( Clk )
.Reset( Reset )
endinsert
Background:
{
[ {a, b} = 0 ]
if ( REG_WE_A == 1 )
a = REG_IN_A
endif
if ( REG_WE_B == 1 )
b = REG_IN_B
endif
}
Сразу же напишем на Автокоде схему компонента «сумматор»:
program summator5
in 32 add1
in 32 add2
out 32 result
in 0 Clk
in 0 Reset
endprogram
declare
enddeclare
Background:
{
[ result = 0 ]
result = add1 + add2
}
Конец схемы примера 5.
Схема компонента «сумматор» получилась совсем простая. Она состоит только из заголовка и разделов начального сброса и действий на каждом такте. В последнем выходному интерфейсному регистру «result» присваивается сумма входных интерфейсных регистров «add1» и «add2».
В модифицированной схеме сложения двух чисел, приведенной выше, компонент «сумматор» объявлен в разделе объявления переменных, и вставлен в схему при помощи оператора «insert» в разделе комбинационной логики. При этом задано соответствие регистров схемы, в которую компонент вставлен, интерфейсным регистрам вставленного компонента.
В терминах аналогии с традиционными языками:
- компонент «сумматор» - вызываемая функция (может быть, более уместна аналогия даже не с функцией, а с макросом),
- add1, add2 и result - ее формальные параметры,
- модифицированная схема сложения двух чисел - вызывающая программа,
- оператор «insert» - вызов функции,
- a, b и sum - аргументы вызова (фактические параметры),
- Clk и Reset - скрытые параметры, смысл которых разъясняется в описании языка Автокод.
Теперь поговорим о различиях компонентов и функций (подпрограмм) традиционных языков программирования.
Самое простое и чисто техническое отличие - в том, что параметры вставки компонента - ключевые, а не позиционные. Соответствие фактических параметров формальным задается по именам, а не по порядку объявления в «program» - «endprogram».
Второе важное различие - смысловое. В традиционных языках программирования вызов функции с передачей ей параметров - это действие, выполняемое в процессе выполнения вызывающей программы в определенный момент времени. Если этот момент времени еще не наступил, вызываемая функция не выполняется, «лежит мертвым грузом».
В противоположность этому, «вызов» компонента в Автокоде - понятие «пространственное», а не «временное». «Вызов» этот (который правильно называть вставкой) выполняется во время трансляции схемы. Транслятор, встретив оператор «insert», порождает очередной экземпляр «вызываемой» схемы и вставляет его в «вызывающую» путем выполнения соединений («припаивания проводов», «соединения разъема»), заданных в операторе «insert». Если один и тот же компонент «вызван» пять раз, он будет присутствовать в оттранслированной схеме пять раз, будучи вставлен в пять разных мест. Каждая такая вставка компонента постоянно работает в общем для всей схемы дискретном времени, а не вызывается в определенные моменты, подобно функциям традиционных языков программирования. Именно по этой причине оператор «insert» может быть записан только в разделе комбинационной логики: провод может быть либо припаян, либо нет, и никакие моменты времени здесь ни при чем.
Словом, компонент и его вызов - это чисто изобразительное средство Автокода. В готовой (оттранслированной и собранной) схеме никаких компонентов нет, а есть единый для всей схемы раздел комбинационной логики, единый раздел начального сброса и т. п. В частности, результатом трансляции и последующей сборки приведенного только что тривиального примера будет схема в машинном виде, идентичная первоначальному варианту схемы сложения двух чисел.
Обсуждая семантику вызова функций и подпрограмм в традиционных языках программирования, обычно довольно много времени уделяют такому явлению, как побочный эффект вызова функции (подпрограммы). В С и Фортране, например, вызываемая функция (подпрограмма) имеет массу возможностей изменить значения переменных, видимых в вызывающей программе, но не являющихся фактическими параметрами вызова. В Автокоде побочных эффектов не бывает. Всякое взаимодействие «вызывающего» и «вызываемого» - только через «разъем» (интерфейсные регистры). Пусть текст программы этого примера находится в файле primer_5.c, а текст схемы - в файлах primer_5.avt (основной текст) и summator.avt (текст компонента - сумматора). Тогда для запуска гибридного приложения необходимо выполнить следующее:
fpga_compile_32 -o primer_5 primer_5.c
- Трансляция данной схемы состоит из двух действий:
- генерация заголовочного файла дополнительного компонента summator5
(формирование в автоматически создаваемой при необходимости директории USERCOMPONENTS файла
summator5.h):
extract_header summator5.avt
- собственно трансляция схемы:
mpirun -np 1 -maxtime 400 `which avts` -vivado primer_5.avt summator5.avt
- генерация заголовочного файла дополнительного компонента summator5
(формирование в автоматически создаваемой при необходимости директории USERCOMPONENTS файла
summator5.h):
- Далее, как и в предыдущих примерах, запуск программы:
mpirun -np 1 -maxtime 10 -resource fpga=k7 primer_5
Теперь мы готовы строить содержательный пример, которому посвящен настоящий раздел. Разработаем схему, выполняющую следующие вычисления:
arr_C = (arr_A + arr_B) * arr_Aгде arr_A и arr_B - два исходных массива чисел типа float указанной длины L,
arr_C - массив результатов поэлементных вычислений.
Управляющая программа для него достаточно похожа на программу примера 4 с поправкой на типы данных (предположим, что размеры машинного представления типов int и float совпадают), поэтому запишем ее без детальных пояснений:
#include <stdio.h>
#include <avtokod/comm.h>
#define L 128
int main( void )
{
int i, num;
WORD result;
static float arr_A[L], arr_B[L], arr_C[L];
init_coprocessor( 0, 0 );
for ( i = 0; i < L; i++ )
{
arr_A[i] = (float)i;
arr_B[i] = (float)i;
arr_C[i] = 0.0;
}
to_register_masked_int( 7, 0, 0 ); // передача в схему адреса ram arr_A =0
to_coprocessor(0, arr_A, L ); // запись массива в ram arr_A
to_register_masked_int(7, 0, 1 ); // передача в схему адреса ram arr_B =1
to_coprocessor(0, arr_B, L ); // запись массива в ram arr_B
to_register( 6, L );
done:
from_register(6, &result );
if ( !result ) goto done;
from_coprocessor(0, arr_C, L ); // чтение массива из ram arr_С
for ( i =0; i < L; i++ )
{
printf( "arr_C[%d] = %f;/n", i, arr_C[i]);
}
return 0;
}
А теперь займемся разработкой схемы, вычисляющей искомое выражение. Хороший стиль программирования: все вычисления, которые можно конвейеризовать, оформляются в виде отдельного компонента. Если бы вычисляемое выражение состояло из одной арифметической операции, то мы воспользовались бы готовым библиотечным компонентом, если больше, то придется создавать свой компонент, в который будут включены необходимые компоненты из библиотеки. Сам компонент, назовем его summator6, запишем позже, а сейчас определим, какие данные нам надо на него подать, какие из него получить и как, используя этот компонент, написать основную схему.
Вычислить надо выражение:
(arr_A + arr_B) * arr_Aзначит, на вход компонента надо подать массивы arr_A и arr_B, с выхода получить массив результатов вычислений. Поскольку арифметические операции с плавающей точкой выполняются с задержкой больше 1-го такта (причем у разных операций задержки могут быть различны), то хотелось бы получить из компонента сигнал, “говорящий” о начале и завершении потока результатов, выдаваемых компонентом. Но, чтобы компонент смог его сформировать, на его вход необходимо подать сигнал, “говорящий” о начале и завершении потоков исходных данных. Такие сигналы называются сигналами разрешения (для входных данных) и сигналами готовности (для выходных). Кроме того, библиотечным компонентам необходим входной сигнал Clk. До сих пор мы рассматривали его как «заклинание». Теперь пришло время узнать, в общих чертах, его смысл.
В действительности, этот «сигнал» не является сигналом строго в том смысле, какой мы вкладывали в это понятие до сих пор. Это служебный синхроимпульс, формируемый задающим генератором на специальном входе микросхемы ПЛИС, и задающий ритм тактов (течение дискретного времени). Любой компонент, использующий присваивания в тактированной части (а библиотечные компоненты плавающей арифметики их используют) обязаны на входе иметь данный сигнал.
Начало схемы примера 6:program vector_proc_32
out 32 DO
in 32 ADDR
in 32 DI
in 1 EN
in 1 WE
in 32 REG_IN_A
in 32 REG_IN_B
out 32 REG_OUT_A
out 32 REG_OUT_B
in 2 REG_WE_A
in 2 REG_WE_B
in 0 Clk
in 0 Reset
endprogram
declare
component summator6
ram 32 arr_A(ramb, 1,2048)
ram 32 arr_B(ramb, 1,2048)
ram 32 arr_C(ramb, 1,2048)
reg 32 ready
reg 32 compute_out
reg 24 L
reg 24 addr_read
reg 24 addr_write
reg 1 compute_we
reg 1 compute_rdy
reg 0 address_ram
enddeclare
insert summator6
.in1(arr_A.doutb) // входные данные из массива arr_A
.in2(arr_B.doutb) // входные данные из массива arr_B
.result(compute_out) // выходные данные массива результатов
.we(compute_we) // сигнал разрешения входных данных
.rdy(compute_rdy) // сигнал готовности выходных данных
.Clk(Clk)
endinsert
{arr_A.dina, arr_B.dina} = DI
{arr_A.addra, arr_B.addra, arr_C.addrb} = ADDR(23:0)
arr_A.wea = (address_ram == 0) ? WE : 0
arr_B.wea = (address_ram == 1) ? WE : 0
DO = arr_C.doutb
{arr_A.addrb, arr_B.addrb} = addr_read
arr_C.addra = addr_write
arr_C.dina = compute_out
arr_C.wea = compute_rdy
REG_OUT_A = ready
Background:
{
[
ready = 1
compute_we = 0
]
if(REG_WE_B == 1)
address_ram = REG_IN_B(0)
endif
if( compute_rdy == 0 )
addr_write = 0
else
addr_write++
endif
}
loop0:
{
if(REG_WE_A == 1)
L = REG_IN_A(23:0)
addr_read = 0
ready = 0
else
next loop0
endif
}
loop1:
{
if( addr_read < L )
addr_read++
compute_we = 1
next loop1
else
compute_we = 0
endif
}
loop2:
{
if(compute_rdy == 1)
next loop2
else
ready = 1
next loop0
endif
}
Конец схемы примера 6
Давая пояснения к тексту, не будем останавливаться на объяснении уже знакомых по предыдущим примерам конструкций. Разберем подробно логику работы с вычислительным компонентом.
В комбинационной части схемы оператором insert мы включили наш компонент summator6, который будет выполнять нужные вычисления и выдавать результаты на регистр compute_out. Сопровождать результаты будет сигнал готовности compute_rdy. Это означает, что когда результатов на регистре compute_out еще нет или уже нет, то compute_rdy = 0, когда на регистре начнут появляться результаты, то сигнал станет равным 1. Сколько тактов compute_rdy будет равным 1? Т.к. вычисления - потоковые, то ровно L тактов: ведь именно такова длина получаемого потока результатов, начиная с [0]-го и кончая [L-1]-м словом.
Тогда, записав в комбинационной части:
arr_C.addra = addr_write
arr_C.dina = compute_out
arr_C.wea = compute_rdy
а в
разделе действий на каждом такте:
if( compute_rdy == 0 )
addr_write = 0
else
addr_write++
endif
мы
обеспечим последовательную запись результатов в ram
arr_C
по адресам с 0 до L-1 включительно.
Последний такт, на котором compute_rdy
= 1, заставит выполниться addr_write++,
что приведет к появлению на следующем такте адреса = L,
но признак записи arr_C.wea
к этому времени уже станет равным 0, что предотвратит запись по
нежелательному адресу.
Сигнал compute_rdy - это сигнал готовности выходного потока compute_out. Но, как было сказано выше, для его правильного формирования в компоненте нужен сигнал разрешения входных потоков. Этот сигнал должен быть равен 1, когда в компонент поступают потоки входных данных, в любое другое время он должен быть равен 0. В схеме он объявлен как одноразрядный регистр compute_we. Управление этим сигналом происходит в разделе последовательных действий. Естественно, в секции начального сброса необходимо включить запись:
compute_we = 0
В 1-м состоянии (метка loop0), в момент появления последнего параметра, устанавливаем в исходное состояние счетчик адресов чтения:
addr_read = 0и переходим на следующем такте во 2-е состояние (метка loop1).
Это цикл чтения данных из массивов arr_A и arr_B. Длится он L+1 тактов. Поскольку данные на выходе из памяти появляются через такт после подачи адреса, а начальный адрес установлен до цикла, то появление нулевых значений arr_A и arr_B совпадет с переключением compute_we в 1 на втором такте цикла. Чтобы сигнал compute_we = 1 длился ровно L тактов, обнулить его надо на последнем такте цикла в ветке else.
В последнем состоянии (метка loop2) пишется окончание работы. Поскольку работа завершится после последней записи в массив arr_C, приходится ждать, пока признак записи compute_rdy не станет равным 0, и только тогда посылать сигнал об окончании работы, и выполнять переход в исходное состояние.
Теперь, когда основная схема написана, можно приступить к разработке схемы компонента summator6. Запишем исходную формулу в развернутом виде:
result_add = in1 + in2 result_mul = result_add * in1где in1 и in2 - интерфейсные регистры входных данных; result_add и result_mul - внутренние регистры результатов сложения и умножения. Для сложения используем готовый библиотечный компонент floating32_add_5, для умножения - floating32_mul_5. В именах библиотечных арифметических компонентов отражается информация о ширине данных (32 разряда) и задержке выполнения операции (5 тактов). Интерфейсные регистры компонентов следующие:
| - первый операнд (32 разряда), | |
| - второй операнд (32 разряда), | |
| - результат сложения или умножения (32 разряда), | |
| - сигнал разрешения входных данных (бит), | |
| - признак готовности результата (бит), | |
| - синхросигнал, обеспечивающий тактирование (бит). |
Данные компоненты имеют задержку 5 тактов и работают в режиме конвейера, т.е. очередные пары операндов можно подавать на входы на каждом такте, но результаты начнут поступать на выход с задержкой в пять тактов относительно поступления соответствующих операндов.
Сигналы operation_nd и rdy имеют ровно тот же смысл, что и сигналы compute_we и compute_rdy, о которых говорилось выше.
Начало схемы компонента:program summator6
in 32 in1
in 32 in2
out 32 result
in 1 we
out 1 rdy
in 0 Clk
endprogram
declare
component floating32_add_5
component floating32_mul_5
reg 32 result_add
reg 32 result_mul
reg 32 in1W(5)
reg 0 rdy_add
reg 0 rdy_mul
enddeclare
result = result_mul
rdy(0) = rdy_mul
insert floating32_add_5
.a(in1) // первое слагаемое in1
.b(in2) // второе слагаемое in2
.operation_nd(we(0)) // разрешение записи we
.result(result_add) // результат сложения result_add
.rdy(rdy_add) // готовность результата rdy_add
.clk(Clk)
endinsert
insert floating32_mul_5
.a(result_add) // первый сомножитель result_add
.b(in1W[4]) // второй сомножитель in1W[4]
.operation_nd(rdy_add) // разрешение записи rdy_add
.result(result_mul) // результат сложения result_mul
.rdy(rdy_mul) // готовность результата rdy_mul
.clk(Clk)
endinsert
В заголовке схемы мы описали все необходимые интерфейсные регистры (об их назначении сказано выше).
В разделе деклараций объявили два необходимых компонента и внутренние регистры, которые понадобятся в схеме.
В комбинационной части записаны включения двух библиотечных компонентов, реализующих сложение и умножение чисел с плавающей точкой. Из текста виден принцип формирования конвейера: каждый компонент принимает на вход либо исходные данные и сопровождающий их сигнал разрешения, либо результат предыдущих вычислений и сопровождающий его сигнал готовности результата, а на выход выдает свои результаты и сигнал готовности. Все было бы просто, если бы не второй сомножитель in1W[4] и не вопрос, какой сигнал выбрать для порта operation_nd: сопровождающий 1-й операнд или 2-й. Здесь мы подходим к одному из ключевых понятий потоковых вычислений - синхронизации потоков.
На первом такте полезной работы нашего компонента на вход поступят in1[0] и in2[0], на втором - in1[1] и in2[1] и т.д. Первый результат сложения result_add[0] появится на выходе floating32_add_5 через 5 тактов, когда на входе будет уже in1[5], поэтому на вход умножителя in1 подавать никак нельзя, его необходимо где-то задержать на 5 тактов. Векторный регистр in1W, с длиной вектора wblock = 5, исполняет роль такой линии задержки:
Продолжение схемы компонента:Background:
{
in1W[0] = in1
do
@1 = 1, 4
in1W[@1] = in1W[@1 - 1]
enddo
}
Конец схемы компонента
Для линии задержки взят векторный регистр только для краткости записи через цикл do. Если цикл развернуть, то запись была бы следующая:
in1W[0] = in1 in1W[1] = in1W[0] in1W[2] = in1W[1] in1W[3] = in1W[2] in1W[4] = in1W[3]
Для традиционной программы запись достаточно бессмысленная, но для схемы имеет вполне определенное значение, если данное присваивание записано в тактированной части. Первый элемент in1 на выходе in1W[0] появиться спустя 1 такт, на выходе in1W[1] - спустя 2 такта, …, на выходе in1W[4] - спустя 5 тактов. Таким образом, мы синхронизировали потоки result_add и in1, подав на умножитель result_add и in1W[4]. Понятно, что если бы на in1 подавали не массив, а константу, то синхронизация была бы не нужна.
Таким образом, при построении конвейера для каждой операции необходимо знать задержку 1-го и 2-го операндов. Если задержки не равны, то для операнда с меньшей задержкой необходимо строить линию задержки, равную их разнице, а на разрешение записи operation_nd подавать сигнал готовности от операнда с большей задержкой. Задержка результата операции будет равна большей задержке операнда плюс задержка самой операции. В нашем случае задержка окончательного результата = 10 тактов.
Пусть текст программы этого примера находится в файле primer_6.c, а текст схемы - в файлах primer_6.avt (основной текст) и summator6.avt (текст компонента). Тогда для запуска гибридного приложения необходимо выполнить следующее:
fpga_compile_32 -o primer_6 primer_6.c
extract_header summator6.avt
mpirun -np 1 -maxtime 400 `which avts` -vivado primer_6.avt summator6.avt
mpirun -np 1 -maxtime 10 -resource fpga=k7 primer_6
Завершающая схема: вычисление определенного интеграла методом трапеций с плавающей точкой (пример №7).
Для выполнения задачи необходимо передать в схему массив вещественных чисел, длину массива и шаг сетки. В схеме нужно сначала разделить пополам первый и последний элементы массива, а затем сложить все элементы массива, а полученную сумму умножить на шаг сетки.
Управляющая программа будет иметь вид:
#include <stdio.h>
#include <avtokod/comm.h>
#define L 128
int main( void )
{
int i, r;
float result, step=0.2;
static float array[L];
init_coprocessor( 0, 0 );
to_register(7, (WORD)step );
for ( i = 0; i < L; i++ ) array[i] = (float)i+1.0;
to_coprocessor( 0, array, L );
to_register( 6, L);
done:
from_register( 6, &r );
if ( !r ) goto done;
from_register( 7, (WORD*)(&result) );
printf( "result: %f\n", result );
return 0;
}
Схема будет состоять из 2-х частей: основная и компонент, выполняющий скалярное суммирование. Начнем с записи компонента summator7.avt.
Как реализовать последовательное суммирование массива вещественных чисел, если задержка операции сложения равна минимум 5 тактов (для 64 и 128 разрядных чисел она больше)? Если строить процесс по аналогии с универсальным процессором, то сначала на сумматор надо подать 2 первых элемента массива, подождать 5 тактов до появления результата, затем подать на сумматор 1-й результат и 3-й элемент, опять подождать 5 тактов, подать 2-й результат и 4-й элемент и т.д. до исчерпания массива. Очевидно, что при таком решении процессор с задачей справится гораздо быстрее, чем схема. Поэтому воспользуемся возможностью строить векторно-конвейерные схемы.
В основной схеме расположим исходный массив в массиве векторной памяти array, векторность которого, допустим, будет равна 8. Тогда на компонент-сумматор можно подавать на каждом такте 8 чисел, что реализует векторность вычислений. Чтобы понять, как реализовать конвейерность вычислений, т.е. выполнять на каждом такте полезные действия, изобразим суммирование такого массива в виде блок-схемы:
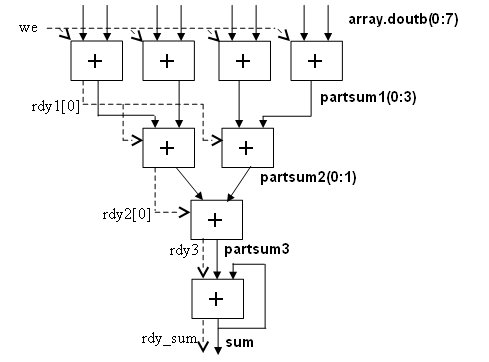
На первые 4 сумматора каждый такт подаются одновременно по 8 чисел массива array, сопровождаемые сигналом разрешения we. Этот сигнал формируется в основной схеме, длится (=1) строго L тактов (длина массива, деленная на 8) и синхронизирует поступление данных из основной схемы. Через 5 тактов после начала работы на векторный регистр partsum1(0:3) начнут поступать по 4 результата сложения, а на rdy(0:3) - 4 сигнала готовности результата, сопровождающие полученные результаты. Данные сигналы идентичны, длятся также L тактов, но сдвинуты относительно we на 5 тактов. Такую же логику построения применяем к следующим двум ярусам сумматоров: входами им будут служить результаты предыдущего яруса, а сигналом разрешения - предыдущий сигнал готовности. В результате получаем один поток частичных сумм partsum3 и сигнал готовности rdy3, его сопровождающий. Сигнал rdy3 тоже длится L тактов, но сдвинут относительно we на 15 тактов. Последний 8-й сумматор (для сложения потока в одну сумму) на блок-схеме изображен упрощенно, для корректного сложения все его связи должны быть более сложными.
Начало схемы компонента:program summator7
in 256 DIN // входные данные массива array
out 32 DO // выходной результат скалярного суммирования
in 1 we // сигнал разрешения входных данных
out 1 rdy // выходной сигнал готовности результата
in 0 Clk
in 0 Reset // в данной схеме необходим начальный сброс
endprogram
declare
component floating32_add_5
reg 32 datain(8)
reg 32 partsum1(4)
reg 1 rdy1(4)
reg 32 partsum2(2)
reg 1 rdy2(2)
reg 32 partsum3
reg 0 rdy3
reg 32 in1
reg 32 in2
reg 32 sum
reg 32 saved_sum
reg 0 we_sum
reg 0 rdy_sum
reg 0 head
reg 0 foot
reg 1 rdy_finish
reg 4 step
enddeclare
datain = split(DIN)
do @1 = 0, 3
insert floating32_add_5
.a( datain[@1*2] )
.b( datain[@1*2+1] )
.result( partsum1[@1] )
.operation_nd( we(0) )
.rdy(rdy1[@1](0))
.clk( Clk )
endinsert
enddo
do @1 = 0,1
insert floating32_add_5
.a(partsum1[@1*2])
.b(partsum1[@1*2+1])
.result(partsum2[@1])
.operation_nd(rdy1[0](0))
.rdy(rdy2[@1](0))
.clk( Clk )
endinsert
enddo
insert floating32_add_5
.a(partsum2[0])
.b(partsum2[1])
.result(partsum3)
.operation_nd(rdy2[0](0))
.rdy(rdy3)
.clk( Clk )
endinsert
В заголовке схемы описаны все интерфейсные регистры, смысл которых понятен, кроме входного регистра DIN. По идее, должно быть 8 входных регистров по 32 разряда. Но это утяжелило бы запись и усложнило бы изменение векторности вычислений. Поэтому разрядность регистра DIN заявлена равной 256 (32*8), на каждые 32 разряда которого из основной схемы будут подаваться данные из векторной памяти, а в комбинационной части компонента регистр DIN раскладывается на вектор datain при помощи функции split:
datain = split(DIN)
Далее в комбинационной части записаны включения 7 библиотечных компонентов floating32_add_5, реализующих конвейер для сложения 8 потоков в один - partsum3. Сопровождает его сигнал готовности rdy3. Остается последовательно сложить все элементы этого потока. Для этого понадобится еще один компонент floating32_add_5, где в качестве 1-го слагаемого будет поток partsum3, а в качестве 2-го - sum, результат сложения этого же компонента. Но, поскольку существует задержка сложения на сумматоре (в данном случае 5 тактов), то придется учитывать 3 фазы процесса сложения:
| 1-я фаза - | начало сложения, поток partsum3 на 1-й вход поступает, а результатов сложения (sum) еще нет, на этот период на 2-й вход необходимо подавать нули; |
| 2-я фаза - | основная часть сложения, поток partsum3 на 1-й вход поступает и есть результаты, следовательно, на 2-й вход подается sum; |
| 3-я фаза - | завершение сложения, поток partsum3 закончился, но в сумматоре еще осталось 5 частичных сумм, которые будут в течение 5 тактов последовательно поступать на регистр sum, для их сложения понадобятся оба входа. |
insert floating32_add_5
.a(in1)
.b(in2)
.result(sum)
.operation_nd(we_sum)
.rdy(rdy_sum)
.clk( Clk )
endinsert
head = rdy3 && ~rdy_sum
foot = ~rdy3 && rdy_sum
we_sum = (rdy3 == 1 || (rdy_sum == 1 && step(0) == 1)) ? 1 : 0
in1 = (rdy3 == 1) ? partsum3 : saved_sum
in2 = (head == 1) ? 0 : sum
rdy = rdy_finish
DO = saved_sum
Background:
{
[ step = 0 ]
if(head == 1)
step+=2
elsif(foot == 1)
saved_sum = sum
if(step > 2)
step--
else
step = 0
endif
endif
if(foot == 1 && step == 2)
rdy_finish = 1
else
rdy_finish = 0
endif
}
Конец схемы компонента.
Переменная head определяет начальную фазу: она равна 1, только когда есть входной поток (rdy3=1) и нет результата (rdy_sum=0).
Переменная foot определяет конечную фазу: она равна 1, только когда уже нет входного потока (rdy3=0), но еще поступает результат (rdy_sum=1).
Сигнал разрешения записи sum_we устанавливается в 1, когда есть входной поток (rdy3=1), или когда есть результат (rdy_sum=1), а значение переменной step - нечетно (step(0)=1). Последнее условие необходимо, чтобы корректно сложить последние 5 чисел, которые будут выходить из сумматора, когда rdy3 станет =0.
Первое слагаемое in1 = partsum3, пока есть входной поток, иначе на него подается задержанный результат суммирования saved_sum. Второе слагаемое in2 = 0, пока входной поток есть, а результатов еще нет, иначе на него подается результат суммирования sum.
Эти присваивания записываются в комбинационной части, чтобы все изменения срабатывали мгновенно. В разделе действий на каждом такте мы формируем условия для корректного суммирования последних 5 чисел (обозначим их как sum[0],sum[1]…,sum[4]) и, после получения окончательной суммы, на один такт ставим в 1 готовность окончательного результата rdy_finish, который вместе с суммой подается на выход компонента.
Переменная step - это реверсивный счетчик. Изначально он устанавливается в 0. На период head=1 на каждом такте он увеличивается на 2, и к наступлению 2-й фазы step станет = 10, если длина входного потока не меньше длины задержки, и = L*2, если меньше. Во второй фазе step сохраняет свое значение. При наступлении 3-й фазы foot =1, step на каждом такте начнет уменьшаться на 1, а в переменную saved_sum будет записываться sum. Подавая в этой фазе на входы in1 = saved_sum и in2 = sum, т.е. задержанное и прямое значение, мы синхронизируем потоки. Подавая на we_sum 1 только при нечетном значении step, мы формируем разрешение записи только для пар sum[0,1] и sum[2,3]. Когда foot станет = 0, step будет =5, а saved_sum = sum[4]. Поскольку было сформировано 2 сигнала we_sum, они вызовут, спустя задержку, появление сигналов rdy_sum, а значит и foot. Данная процедура будет продолжаться до тех пор, пока не совпадет foot = 1 и step = 2, что означает появление окончательного результата. Распишем, что конкретно будет сформировано на тех дополнительных тактах, где foot =1:
step = 5, we_sum=1; in1 = sum[4]; in2 = sum[0,1]; (step--)
step = 4, we_sum=0; (saved_sum = sum[2,3]; step--)
step = 3, we_sum=1; in1 = sum[2,3]; in2 = sum[0,1,4]; (step--)
step = 2 we_sum=0; (saved_sum = sum[0,1,2,3,4]; step=0; rdy_finish = 1).
На следующем такте компонент выдаст в основную схему окончательный результат сложения DO = saved_sum и сигнал готовности rdy = rdy_finish.
Текст компонента написан, сохраним его в файле summator7.avt и приступим к записи основной схемы.
Какую работу необходимо выполнить в основной схеме?
Принять: массив вещественных чисел, записав его в ram array, векторность которого равна 8; целое число (длина массива), записав его в переменную L; вещественное число (шаг сетки), записав его в переменную step.
Выполнить: разделить пополам первое и последнее числа массива, записав результаты в память array, сложить все элементы массива, а полученную сумму умножить на шаг сетки. Окончательный результат сохранить в переменной result и закончить работу.
Для выполнения арифметических операций понадобится созданный нами компонент summator и библиотечный компонент floating32_mul_5 (умножение). Делитель использовать не будем, заменив деление на 2 умножением на 0.5 (во-первых, деление гораздо более длительная и затратная операция, а во-вторых, все 3 операции можно будет выполнить в одном компоненте).
Начало схемы примера 7:program vector_proc_32
out 32 DO
in 32 ADDR
in 32 DI
in 1 EN
in 1 WE
in 32 REG_IN_A
in 32 REG_IN_B
out 32 REG_OUT_A
out 32 REG_OUT_B
in 2 REG_WE_A
in 2 REG_WE_B
in 0 Clk
in 0 Reset
endprogram
declare
component floating32_mul_5
component summator7
ram 32 array(ramb,8,16384)
reg 32 result
reg 32 ready
reg 32 step
reg 32 saved_first
reg 32 saved_last
reg 32 sum_result
reg 32 mul_a
reg 32 mul_b
reg 32 mul_result
reg 24 L
reg 24 addr_read
reg 2 rgm
reg 1 mul_we
reg 1 mul_rdy
reg 1 sum_we
reg 1 sum_rdy
enddeclare
REG_OUT_A = ready
REG_OUT_B = result
do @1 = 0, 7
array.dina[@1] = DI
array.addra[@1](23:0) = (WE == 1) ? ADDR(26:3) : addr_read
array.wea[@1] = ( (@1 == ADDR(2:0)) && (WE == 1) ) ? 1 : 0
enddo
array.addrb[0] = 0
array.addrb[7] = L-1
{array.dinb[0], array.dinb[7]} = mul_result
array.web[0] = (rgm == 0) ? mul_rdy : 0
array.web[7] = (rgm == 1) ? mul_rdy : 0
array.web(1:6) = 0
insert floating32_mul_5
.a(mul_a)
.b(mul_b)
.result(mul_result)
.operation_nd(mul_we(0))
.rdy(mul_rdy(0))
.clk(Clk)
endinsert
insert summator7
.DIN(255:0)(join(array.douta))
.DO(sum_result)
.we(sum_we)
.rdy(sum_rdy)
.Clk(Clk)
.Reset(Reset)
endinsert
В комбинационной части на выходные регистры REG_OUT_A и REG_OUT_B подаются переменные: признак готовности схемы к работе (ready) и результат вычислений (result). Далее описаны комбинационные связи векторной памяти array.
Порт ‘a’ памяти будем использовать для записи поступающего из процессора массива и для чтения элементов массива при скалярном суммировании. Поэтому, при наличии признака внешней записи WE = 1, на регистр адреса array.addra будут поступать старшие разряды внешнего адреса ADDR(26:3), на признак записи в память array.wea - 1, в зависимости от дешифрации младших разрядов адреса ADDR(2:0). При WE = 0 на array.addra подается счетчик адресов по чтению addr_read, а на array.wea - 0.
Порт ‘b’ будем использовать для записи результатов умножения на 0.5 первого и последнего элемента массива. Т.к. векторность ram array равна 8, то первый элемент будет храниться в 0-м, а последний - в 7-м блоке памяти. Задаем адреса в этих блоках array.addrb[0] = 0 и array.addrb[7] = L-1. На регистры array.dinb[0] и array.dinb[7] подаем результат умножения mul_result, а вот признаки записи array.web[0] и array.web[7] придется формировать по-разному. Переменная rgm - признак, отличающий одно произведение от другого. Тогда запись mul_result на 0-й блок произойдет при rgm = 0, а на 7-й блок - при rgm = 1. Задавать значения rgm будем в тактированной части.
Далее описаны включения компонентов:
floating32_mul_5 - умножение пар вещественных чисел. Т.к. таких пар будет 3, то на входы a и b подаются переменные mul_a и mul_b, а в тактированной части этим переменным будет присваиваться то или иное значение.
summator7 - компонент выполняющий скалярное суммирование массива, поступающего с векторного регистра array.douta. Здесь применяется прием, описанный при разборе схемы компонента: для сокращения текста на входной порт DIN, заданный равным 32*8, подается результат выполнения функции join(array.douta). Эта функция «склеивает» разряды векторного регистра в один большой скалярный регистр.
Продолжение схемы примера 7:Background:
{
[
ready = 1
rgm = 0
{mul_we,sum_we} = 0
]
if(REG_WE_B == 1 )
step = REG_IN_B
endif
if(WE == 1)
if(ADDR == 0)
saved_first = DI
endif
saved_last = DI
endif
}
loop0:
{
if( REG_WE_A == 1 )
L(23:0) = REG_IN_A(26:3)
ready = 0
addr_read = 0
mul_a = saved_first
mul_b = float(32, 0.5)
mul_we = 1
else
next loop0
endif
}
{
mul_a = saved_last
}
loop1:
{
mul_we = 0
if(rgm == 0)
if(mul_rdy==0)
next loop1
else
rgm = 1
endif
endif
}
loop2:
{
if(addr_read < L)
addr_read++
sum_we = 1
next loop2
else
sum_we = 0
endif
}
loop3:
{
if(sum_rdy == 0)
next loop3
else
mul_a = sum_result
mul_b = step
mul_we = 1
rgm = 2
endif
}
loop4:
{
mul_we = 0
if(mul_rdy == 0)
next loop4
else
result = mul_result
rgm = 0
ready = 1
next loop0
endif
}
Конец схемы примера 7.
В разделе действий на каждом такте (метка Background) выполняем следующее:
- В секции начального сброса инициализируем переменные ready=1, rgm=0, mul_we=0, sum_we=0.
- Принимаем аргумент step (он появится на REG_IN_B в момент REG_WE_B = 1).
- Во время приема массива запоминаем первый - saved_first и последний - saved_last элементы массива. По условию WE = 1 (разрешение записи числа, находящегося на регистре DI), запись saved_first = DI при адресе ADDR = 0 позволит сохранить первый элемент массива, а запись saved_last = DI , будет сохранять каждый элемент, поэтому после окончании записи массива в переменной останется последний элемент.
Далее записываем раздел состояний.
| 1. | 1-е состояние (метка loop0). | Ожидание начала вычислительной работы, которое наступает в момент прихода последнего аргумента (REG_WE_A = 1). По этому условию сохраняем в переменной L длину массива без младших 3-х разрядов (при векторности, равной 8, адресов у массива будет в 8 раз меньше). Сбрасываем сигнал готовности схемы ready, устанавливаем на addr_read начальный адрес чтения и подготавливаемся к первому умножению: записываем на mul_a и mul_b нужные данные и ставим в 1 разрешение записи mul_we. Признак 1-го умножения rgm = 0 установлен еще в секции начального сброса. |
| 2. | 2-е состояние. | Готовимся ко второму умножению: mul_we оставляем =1, mul_b тоже остается прежним, а на mul_a записываем новое значение saved_last. |
| 3. | 3-е состояние (метка loop1). | Сбрасываем разрешение записи mul_we = 0 и ждем появления 1-го результата умножения mul_rdy = 1, чтобы установить rgm = 1 (признак 2-го умножения). |
| 4. | 4-е состояние (метка loop2). | Здесь записывается основной цикл чтения массива. Читая данные по адресам от 0 до L-1 включительно, держим разрешение записи в сумматор sum_we = 1. В последнем такте цикла, когда addr_read станет = L, сбрасываем разрешение записи в 0. |
| 5. | 5-е состояние (метка loop3). | Ожидание результата суммирования (sum_rdy = 1), чтобы можно было выполнить последнее 3-е умножение. Устанавливаем: mul_a = sum_result, mul_b = step, mul_we = 1, rgm = 2. |
| 6. | Последнее состояние (метка loop4). | Сбрасываем в 0 mul_we и ждем результата умножения. При mul_rdy = 1 сохраняем результат result = mul_result, восстанавливаем исходное состояние rgm = 0, сообщаем о конце работы ready = 1 и возвращаемся в 1-е состояние. |
Для запуска гибридного приложения примера 7 необходимо выполнить:
fpga_compile_32 -o primer_7 primer_7.c
extract_header component7.avt
mpirun -np 1 -maxtime 400 `which avts` -vivado primer_7.avt summator7.avt
mpirun -np 1 -maxtime 10 -resource fpga=k7 primer_7
Результат работы этой программы выглядит так:
result: 1638.20000Часть 2 ►