RefNUMA – библиотека для организации виртуальной общей памяти в программах, использующих MPI.
Пример 3. Создание и использование секционированного массива.
Общий смысл приведенной ниже программы состоит в следующем. Сначала все процессы совместно создают массив общей памяти. Затем каждый процесс заполняет «свою» часть созданного массива некоторыми данными. После этого каждый процесс видит массив общей памяти заполненным данными целиком, включая как «свою» часть, так и «чужие» части. В отличие от предыдущих, совсем тривиальных, примеров, для понимания приведенного ниже текста потребуются некоторые вводные пояснения.
#include <stdio.h>
#include <stdlib.h>
#include <mpi.h>
#include <coarray.h>
#include <shared.h>
#define LSECT 10
COARRAY_MEM_ALLOC( 2000000000l );
int main( int argc, char *argv[] )
{
int i, j, k, my_node, n_nodes;
double **coarray;
FILE *fp;
/***/
COARRAY_Init( &argc, &argv );
my_node = coarray_my_node();
n_nodes = coarray_n_nodes();
coarray = (double**)coarray_create( LSECT*sizeof(**coarray),
LSECT*1000*sizeof(**coarray) );
if ( !coarray )
{
fprintf( stderr, "No memory\n" );
exit( -1 );
}
if ( my_node == 0 )
{
fp = fopen( "output.dat", "w" );
fclose( fp );
}
NODE_BY_NODE_BEGIN( i, 0, n_nodes )
fp = fopen( "output.dat", "a" );
if ( i == 0 ) fprintf( fp, "BEFORE ASSIGNMENT\n" );
fprintf( fp, "Hello, I am %d of %d\n", my_node, n_nodes );
fprintf( fp, "My view of the coarray is:\n" );
for ( j = 0; j < n_nodes; j++ )
{
for ( k = 0; k < LSECT; k++ )
{
fprintf( fp, " %f\n", coarray[j][k] );
}
}
fclose( fp );
NODE_BY_NODE_END
coarray_barrier();
for ( i = 0; i < LSECT; i++ ) coarray[my_node][i] = LSECT*my_node+i;
coarray_barrier();
NODE_BY_NODE_BEGIN( i, 0, n_nodes )
fp = fopen( "output.dat", "a" );
if ( i == 0 ) fprintf( fp, "AFTER ASSIGNMENT\n" );
fprintf( fp, "Hello, I am %d of %d\n", my_node, n_nodes );
fprintf( fp, "My view of the coarray is:\n" );
for ( j = 0; j < n_nodes; j++ )
{
for ( k = 0; k < LSECT; k++ )
{
fprintf( fp, " %f\n", coarray[j][k] );
}
}
fclose( fp );
NODE_BY_NODE_END
COARRAY_Finalize();
return 0;
}
Обращение к функции coarray_create() создает секционированный массив – единственную форму массива общей памяти, которая предусмотрена в RefNUMA.
Создание секционированного массива – коллективная операция, включающая в себя барьерную синхронизацию, то есть все процессы параллельной программы должны вызвать coarray_create() логически одновременно и с одними и теми же значениями аргументов.
Секционированный массив – это набор секций одинакового размера, и массив указателей на эти секции. Секций всегда ровно столько, сколько процессов в параллельной программе. coarray_create() возвращает указатель на массив указателей на секции.
Рис. 1. Секционированный массив в процессе параллельной программы, состоящей из 4-х процессов.
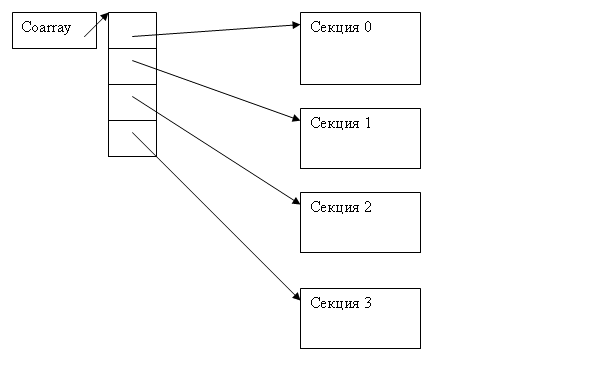
Прежде всего, подчеркнем, что секционированный массив – это массив виртуальной общей (для всех процессов) памяти. Массив указателей на секции, показанный на рисунке слева, в каждом процессе свой, но сами секции существуют в единственном экземпляре, и доступны всем процессам. Например, секция 2, одна из показанных на рисунке справа, это одна область памяти, доступная всем четырем процессам параллельной программы через соответствующие указатели, существующие в каждом из процессов. Мы, конечно, знаем, что в действительности общей памяти у процессов параллельной программы нет. Говоря о существовании одного на всю параллельную программу набора секций, доступного всем процессам, мы описываем виртуальную сущность, то есть некоторую «иллюзию», ради создания которой и разработана библиотека RefNUMA. Программисту, тем не менее, следует писать программу так, как если бы это было «на самом деле», подобно тому, как он использует язык программирования, «как будто бы» процессор компьютера «на самом деле» понимает программы на Фортране или Си.
Создание приятных иллюзий – дело не дешевое, и заниматься этим имеет смысл только в том случае, если есть надежда на эффективную реализацию. Одним из аспектов платы за эффективность как раз и является необходимость разбиения массива общей памяти на секции по числу процессов параллельной программы. Конечно, было бы гораздо удобнее, если бы не было никаких секций, а был один сплошной, виртуально общий, массив, но создание такой иллюзии, к сожалению, не допускает эффективной реализации на современном оборудовании. В последующих примерах мы научимся в значительной степени избавляться от неудобств, вызываемых разбиением массивов общей памяти на секции.
Смысл разбиения массива общей памяти на секции, вкратце, заключается в следующем. Секция номер N «в действительности находится» в процессе номер N, то есть «принадлежит» ему, или является для этого процесса «своей», остальные секции для этого процесса «чужие». Процесс имеет право обращаться как к своей секции, так и к чужой, но программа будет работать быстрее и потребует меньше физической памяти, если каждый процесс будет обращаться, в основном, к данным из своей секции, и только изредка – к данным из чужих секций (в рассматриваемом тривиальном примере эта рекомендация не соблюдается). Подробнее об этом будет рассказано ниже. Здесь мы упомянули об этом свойстве секционированных массивов только для того, чтобы ввести понятие своей и чужой для данного процесса секции.
У функции создания секционированного массива два аргумента, оба входные и имеют тип long. Первый аргумент – это размер секции в байтах, второй аргумент – размер (также в байтах) дополнительной системной памяти, которую разрешается использовать библиотеке RefNUMA для реализации этого секционированного массива. Память эта берется из пула, резервируемого обращением к COARRAY_MEM_ALLOC(). О том, как задавать это значение, поговорим ниже, здесь же отметим, что в данном случае оно задано с достаточным запасом.
Теперь посмотрим на саму программу. Легко видеть, что она делает следующее. Сначала все процессы по очереди печатают содержимое секционированного массива. Поскольку его элементам пока еще ничего не присваивалось, там, скорее всего, будут нули. В конце печати выполняется барьер.
Затем каждый процесс расписывает элементы своей секции массива их (элементов) порядковыми номерами.
Затем выполняется барьер, после чего все процессы снова печатают содержимое секционированного массива. Мы видим, что каждый процесс теперь видит весь массив заполненным номерами его элементов, хотя сам он заполнил номерами только элементы своей секции. Таким образом, память действительно ведет себя как общая: значения, присвоенные элементам массива одним процессом, видны в других процессах.
Очень важно отметить, что результаты присваиваний элементам массива общей памяти, выполненных другими процессами, становятся видны данному процессу не сразу, а только после выполнения coarray_barrier(). Если к coarray_barrier() не обращаться, «доведение» результатов присваиваний «до сведения» других процессов может откладываться на неопределенное время, то есть память перестанет быть общей. Обратное неверно – нельзя рассчитывать на то, что присваивания совершенно точно не будут видны другим процессам, пока не выполнится барьер. Также отметим, что рассматриваемая нами программа (Пример 3) не перестанет работать, если изъять из нее обращения к coarray_barrier(), но только потому, что обращения к coarray_barrier() присутствуют в макросе NODE_BY_NODE_BEGIN(), который используется для синхронизации печати.
Таким образом, когерентность общей памяти подчиняется одному, очень простому, правилу: сразу после барьера все процессы видят все элементы массива общей памяти одинаково.
◄ Пример 2 Пример 4 ►